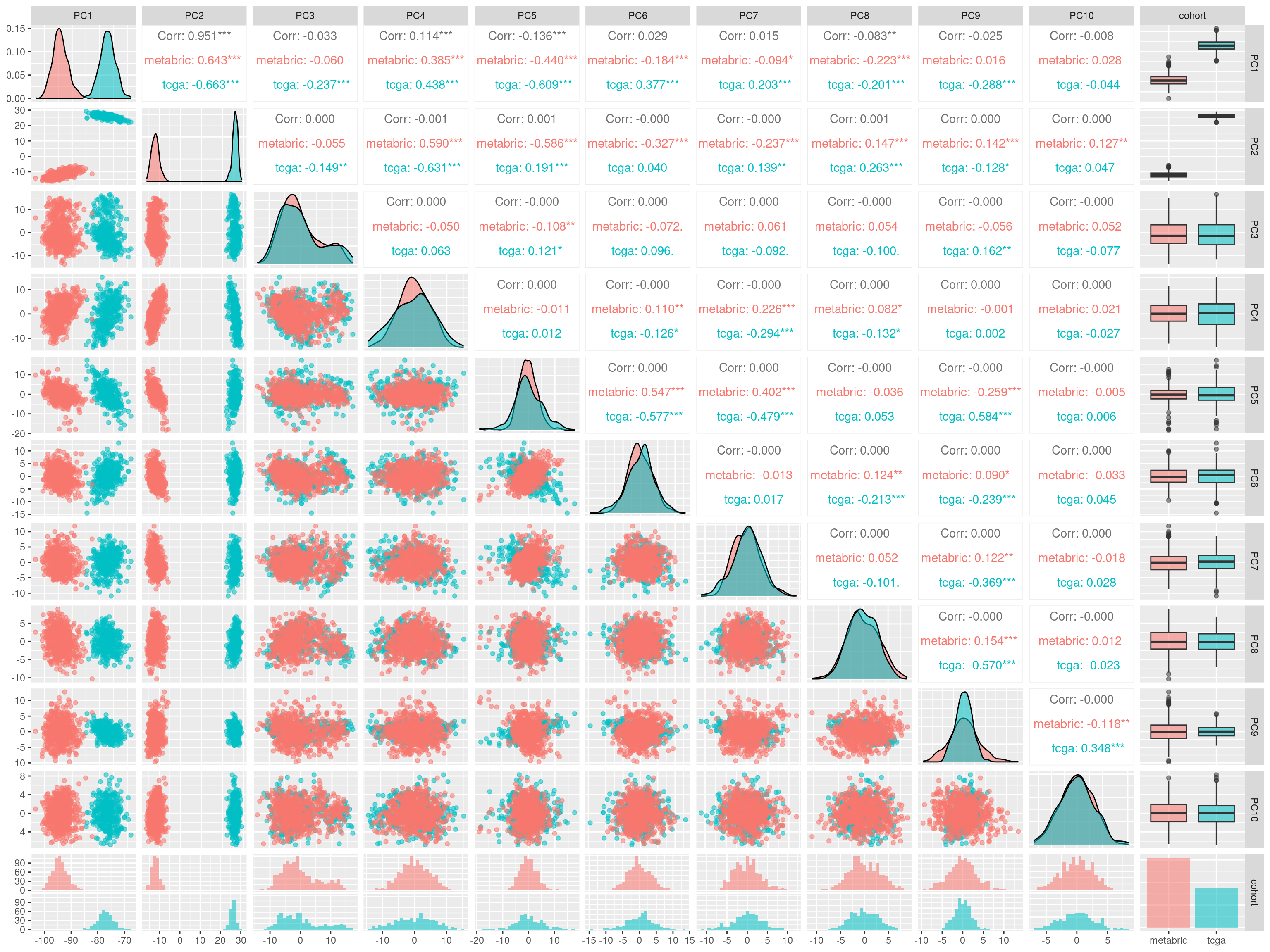
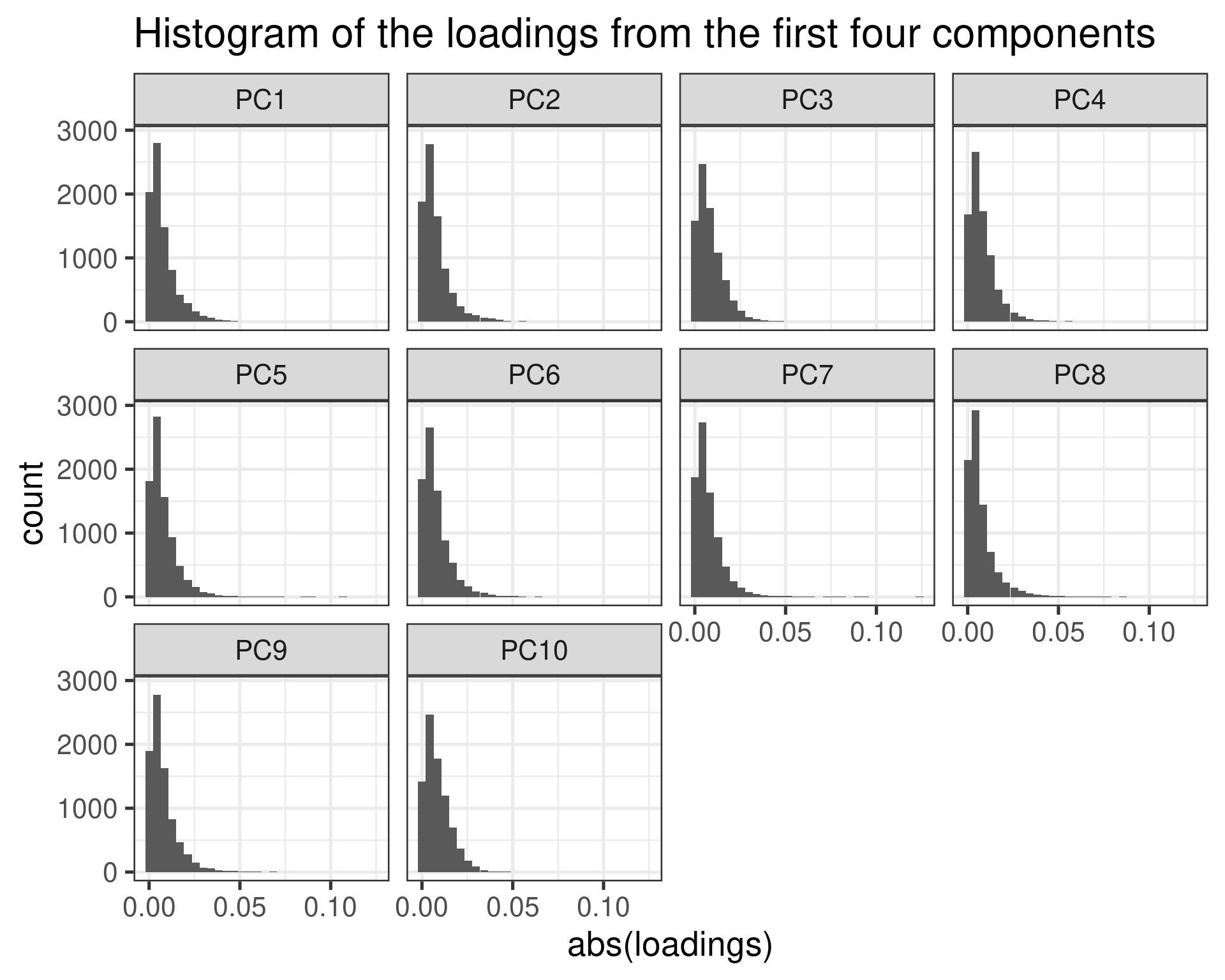
We have used some numbers of genes for doing the embedding. Here we try to perform the embedding with all the genes (~10000 genes) and then we try to regress out the components.
* The library is already synchronized with the lockfile.
Total number of stable genes: 39
Total number of genes: 8248
Number of samples: 1005
Total number of stable genes: 39
Total number of genes: 8248
Number of samples: 7216
Total number of stable genes: 39
Total number of genes: 8248
Number of samples: 1868
Total number of stable genes: 39
Total number of genes: 8248
Number of samples: 426
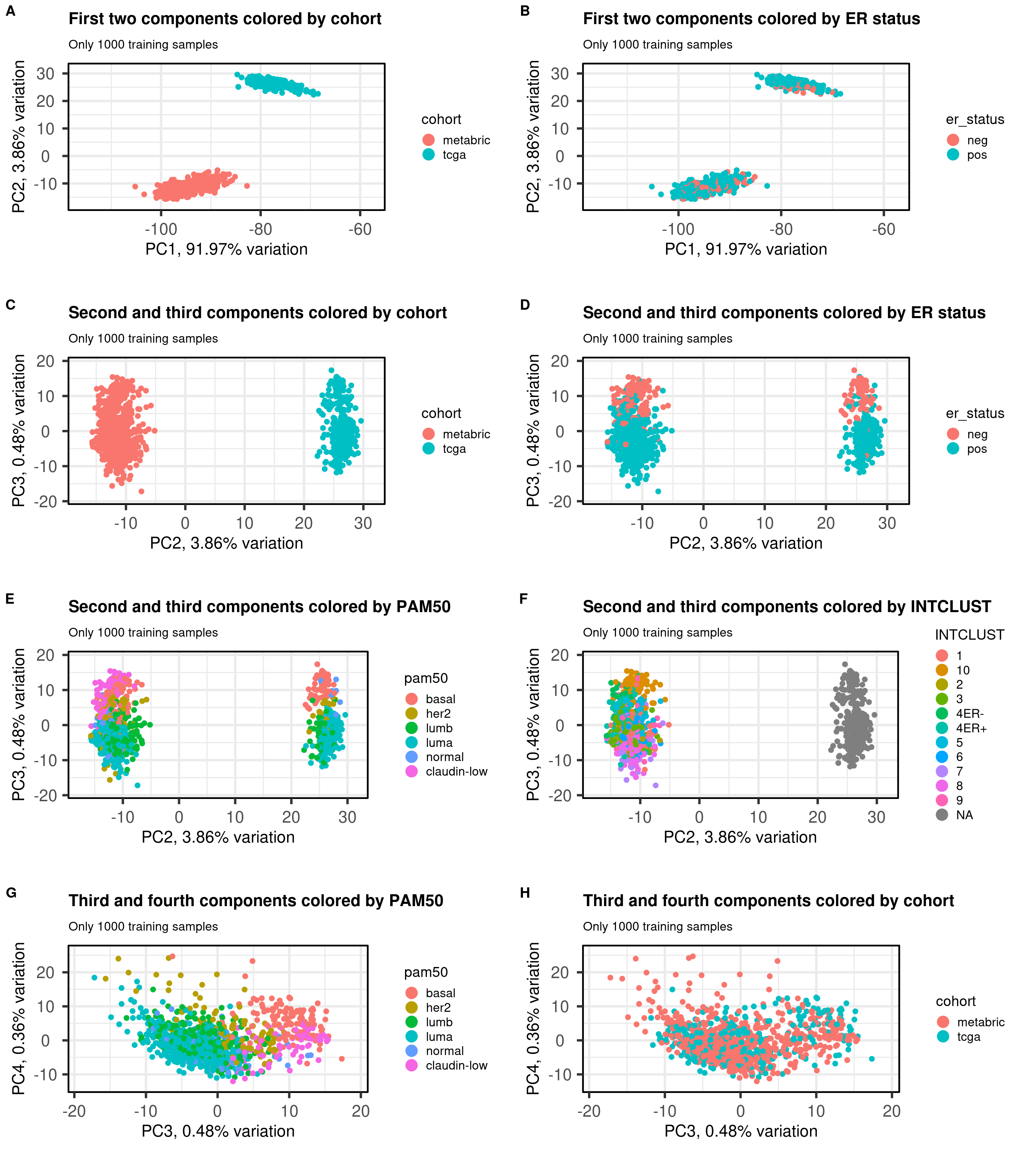
And now we can visualize the results.
Figure 6.1: PCA projections colored by different factors and organized by different components. (A) Plot of the first two components colored by cohort. (B) Plot of the first two components colored by ER status. (C) Plot of the second and third components colored by cohort. (D) Plot of the second and third components colored by ER status. (E) Plot of the second and third components colored by PAM50. (F) Plot of the second and third components colored by INTCLUST, only METABRIC has an assigned value for this variable, NAs are TCGA samples.
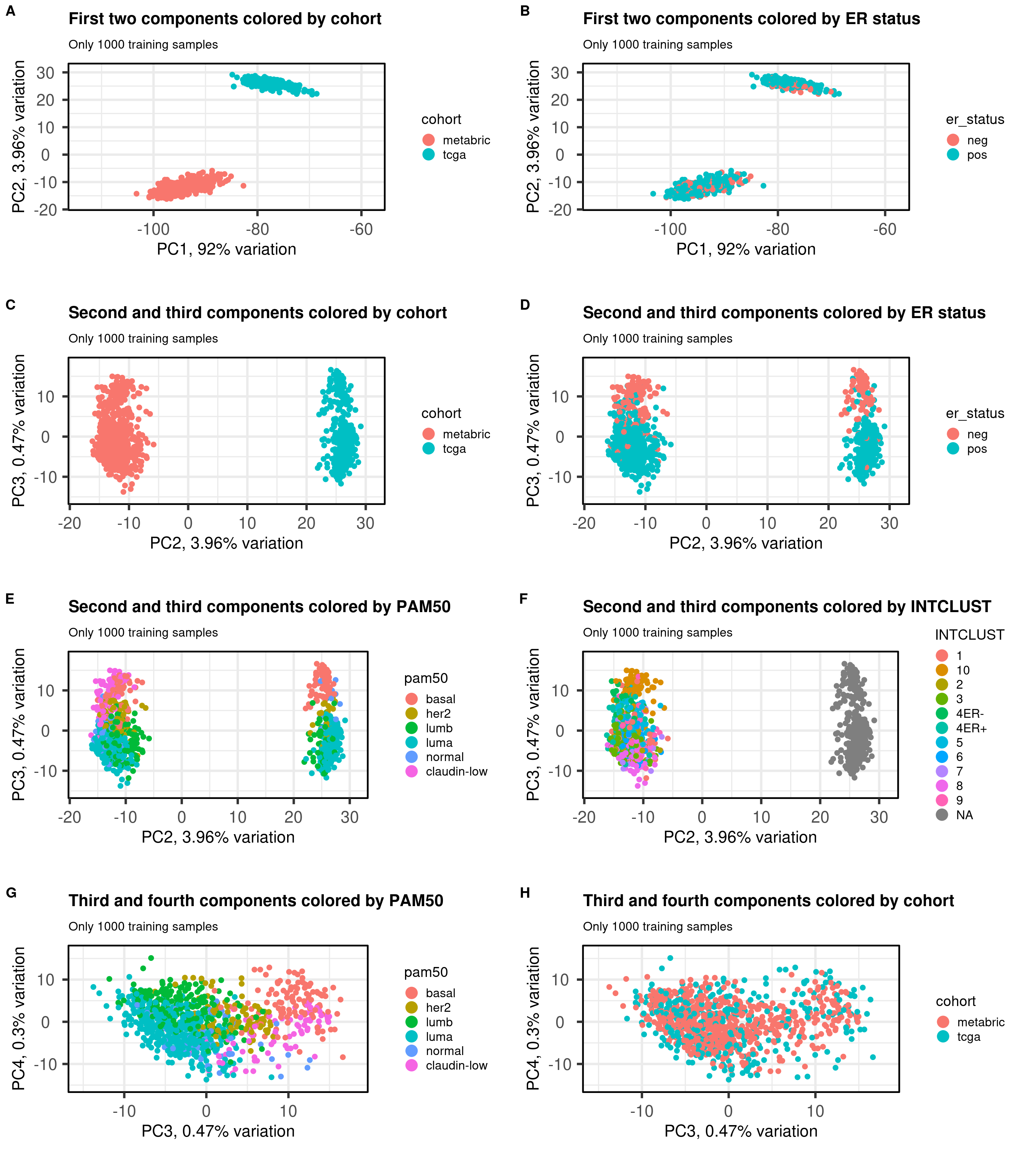
And now we can visualize the results.
Figure 6.2: PCA projections colored by different factors and organized by different components. (A) Plot of the first two components colored by cohort. (B) Plot of the first two components colored by ER status. (C) Plot of the second and third components colored by cohort. (D) Plot of the second and third components colored by ER status. (E) Plot of the second and third components colored by PAM50. (F) Plot of the second and third components colored by INTCLUST, only METABRIC has an assigned value for this variable, NAs are TCGA samples.
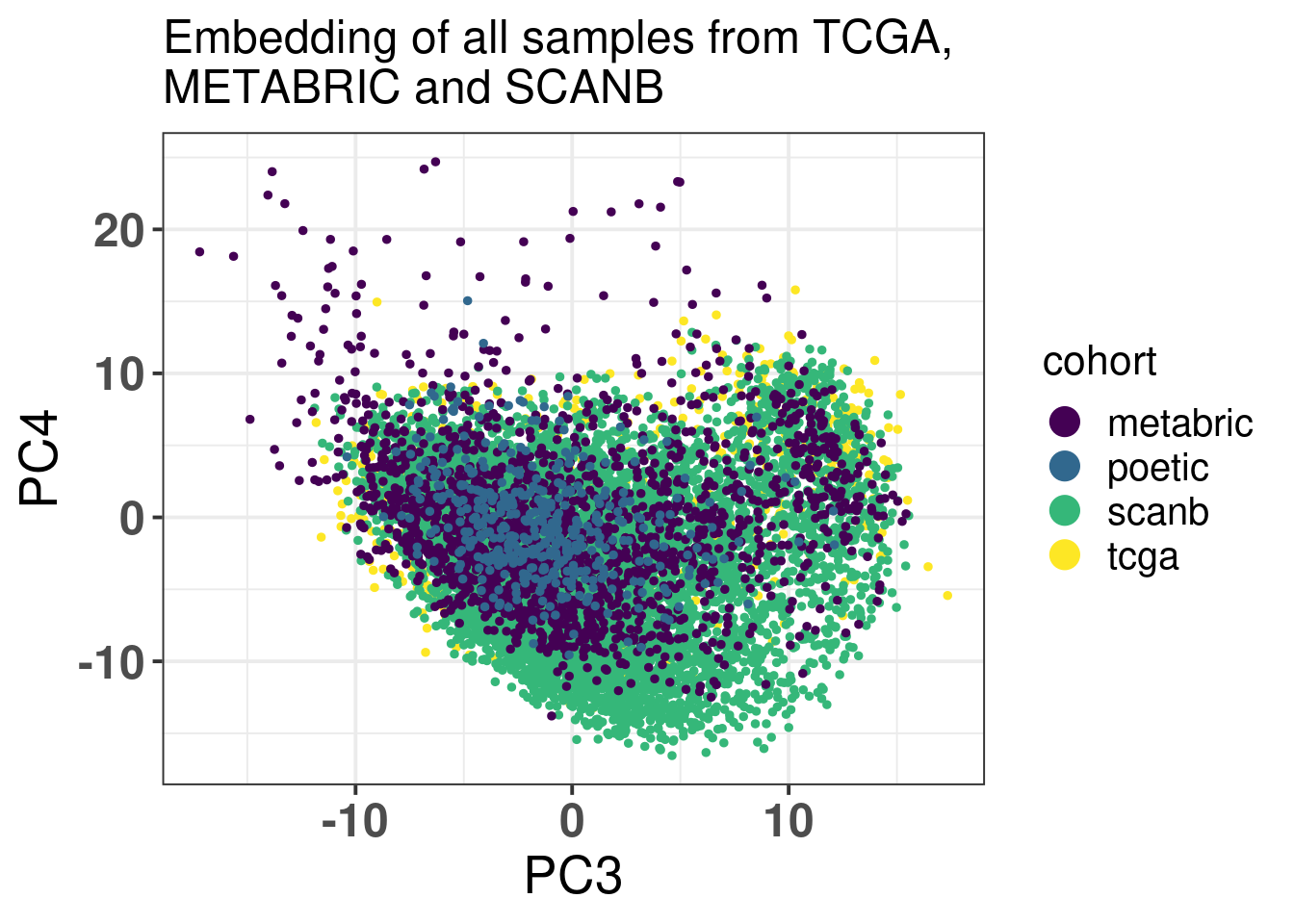
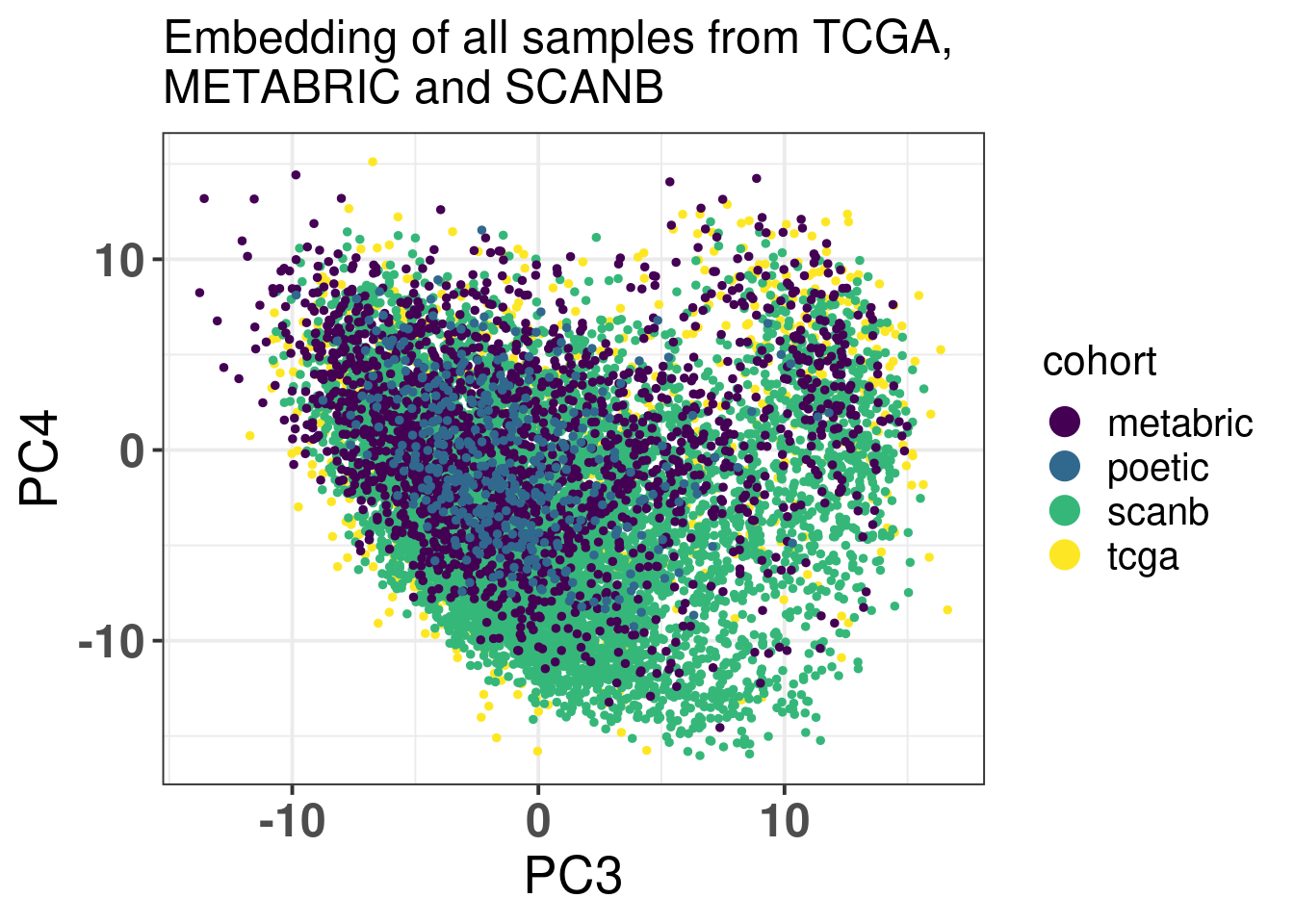
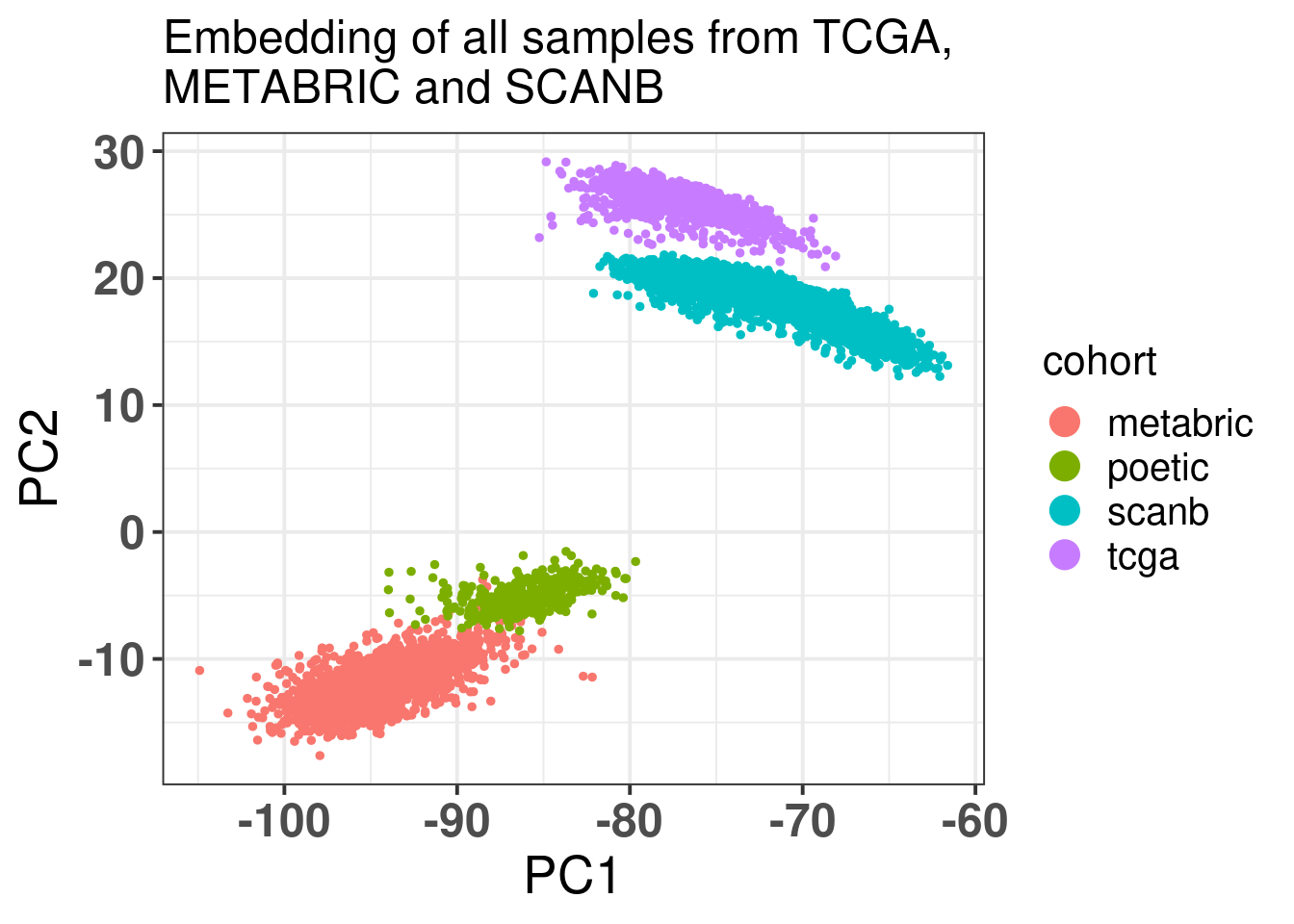
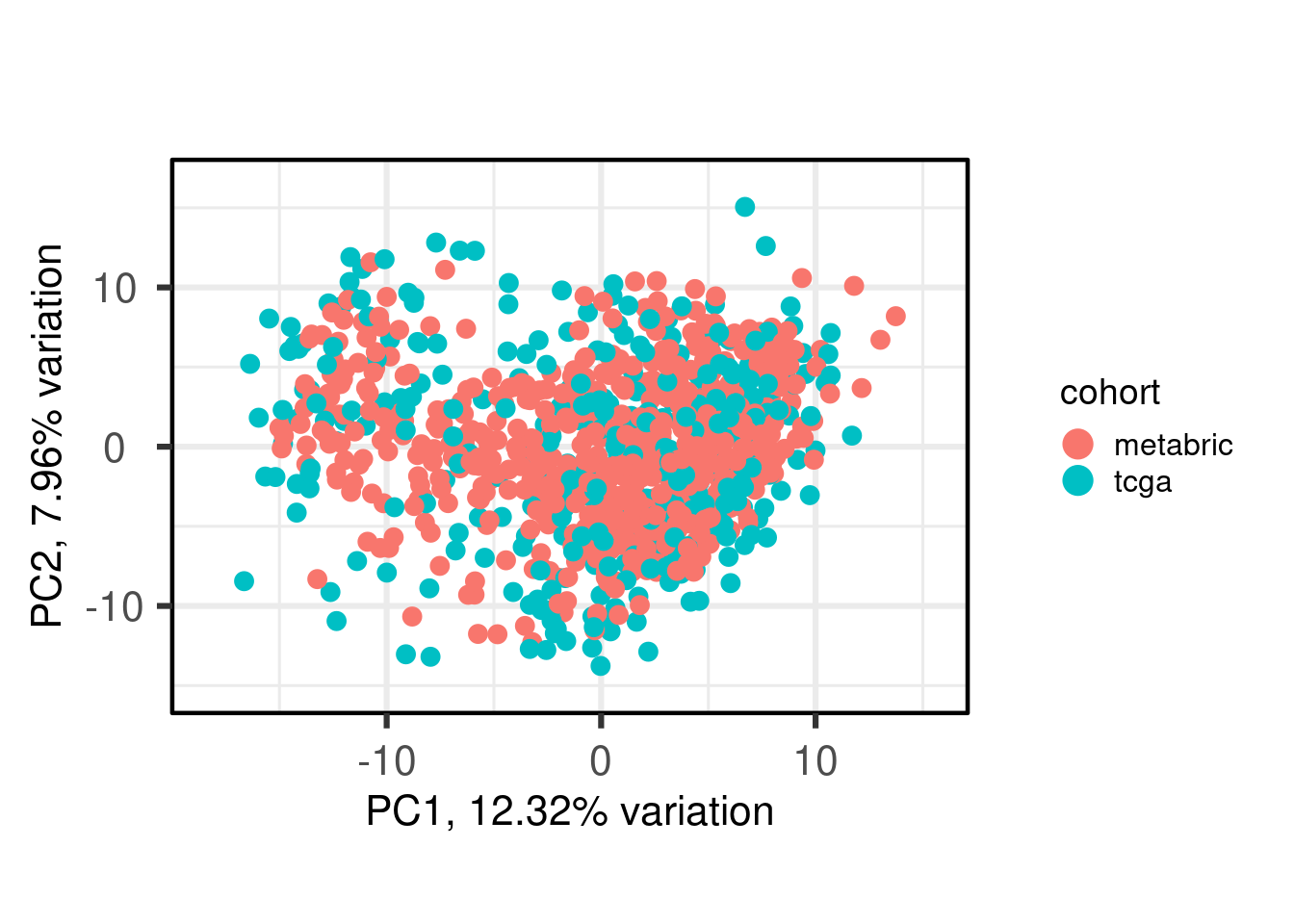
Figure 6.3: PCA embedding colored by cohort. The components used are the first and second components.
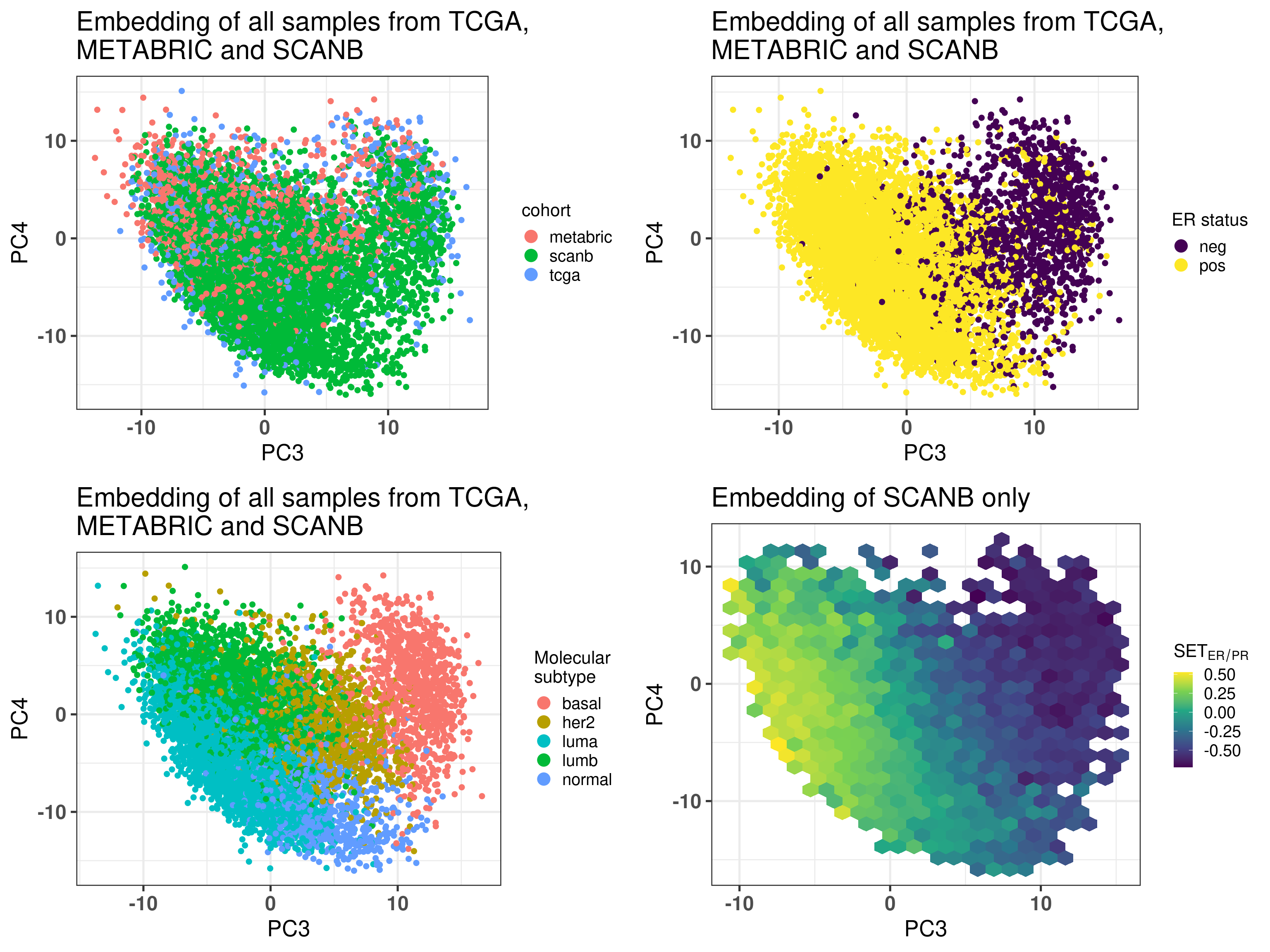
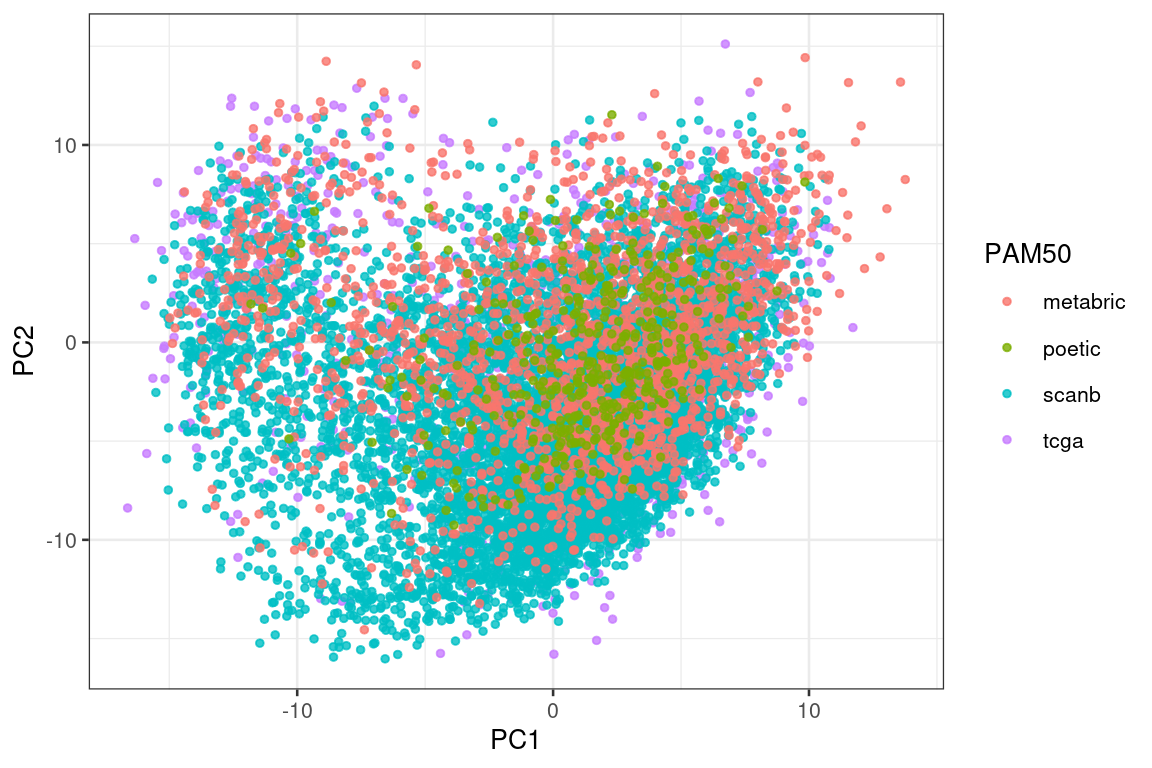
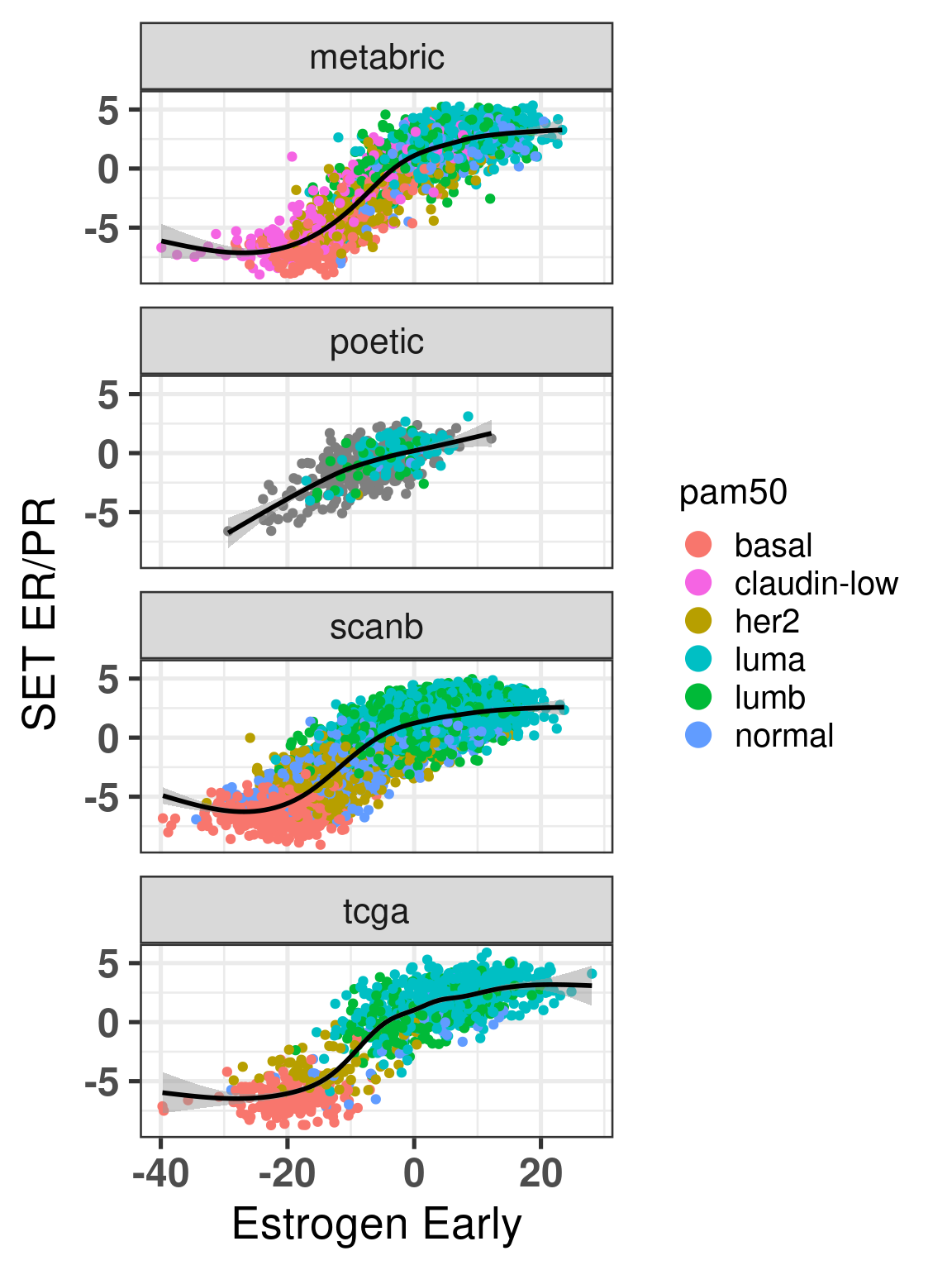
Figure 6.4 shows that the SCANB samples are also well mixed regarding the clinical factors, including the \(SET_{ER/PR}\) signature.
Figure 6.4: PCA embedding of all samples from TCGA, SCANB and METABRIC. (A) Colored by cohort, (B) colored by ER status, (C) colored by PAM50 molecular subtype, (D) colored by the \(SET_{ER/PR}\) signature and only SCANB samples.
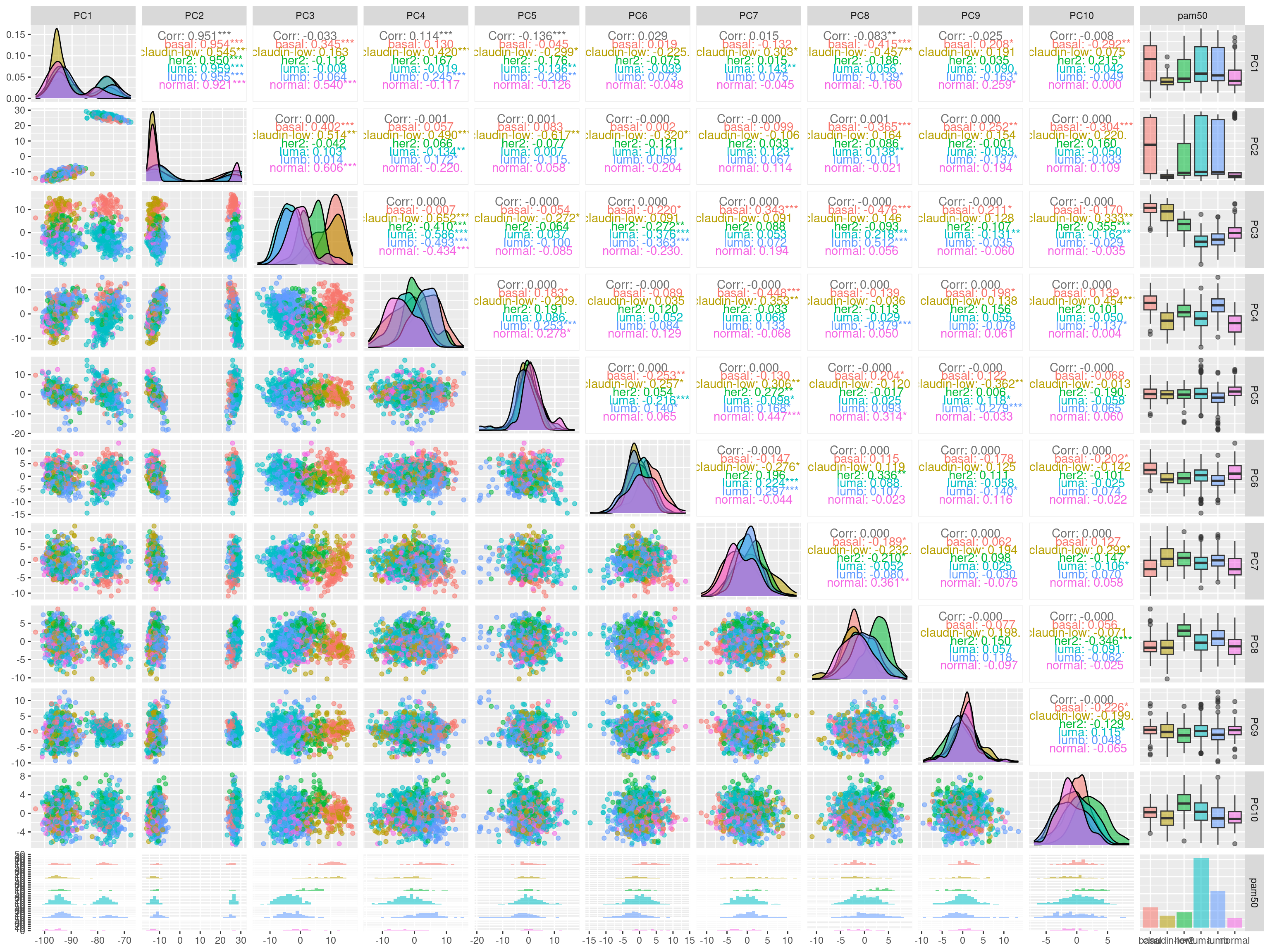
Let us also check the other components in the biplots.
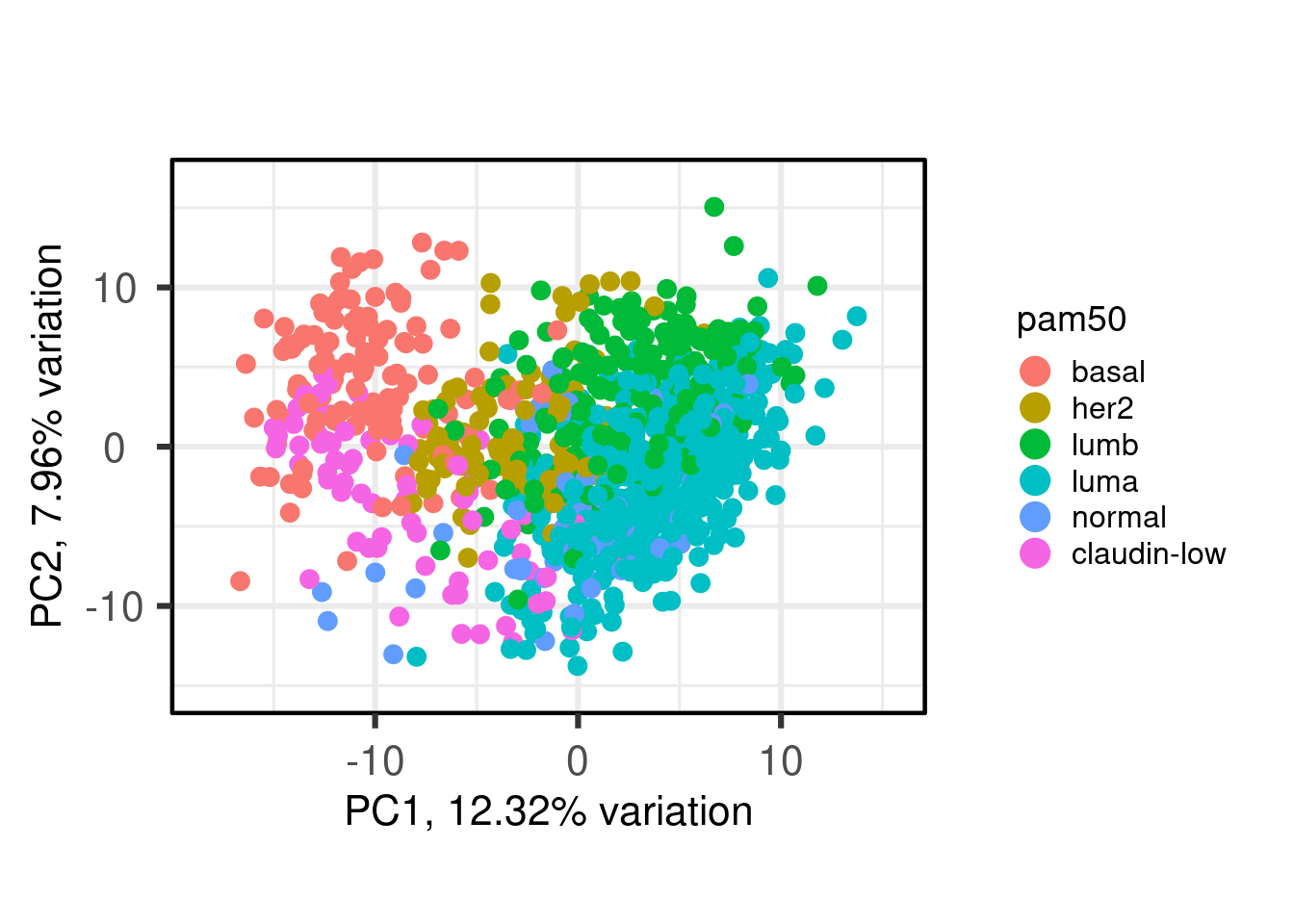
We see that the pam50 subtypes are being separated using the components 3, 4 and also 8. In the component 8 there is some expression that is able to differentiate between HER2-like from all other samples.
We now plot by cohort.
In PC1, 2 and 5 there are some small differences in the differences of the distributions from the datasets. We will then remove these 3 components up to component 10 with exception of components 3, 4 and 5.
6.2 Removing the batch effects
We now try to remove the batch effects by removing all the PCs that are not of interest, so we remove the first two components and the fifth as well. We then calculate the scores for each cohort separately and then compare to what was calculated before. We can then try to calculate the scores using samples coming from all cohorts.
In general it looks good, the luminal B population is a bit compressed towards the luminal A population though.
There is a very good merging of the datasets. We see mostly green points because they are the majority.
Now we see that the first loadings has a tail in a similar fashio as the other loadings.
We now try to calculate the scores of the samples using these new embeddings only from TCGA samples as we will compare the results later on.
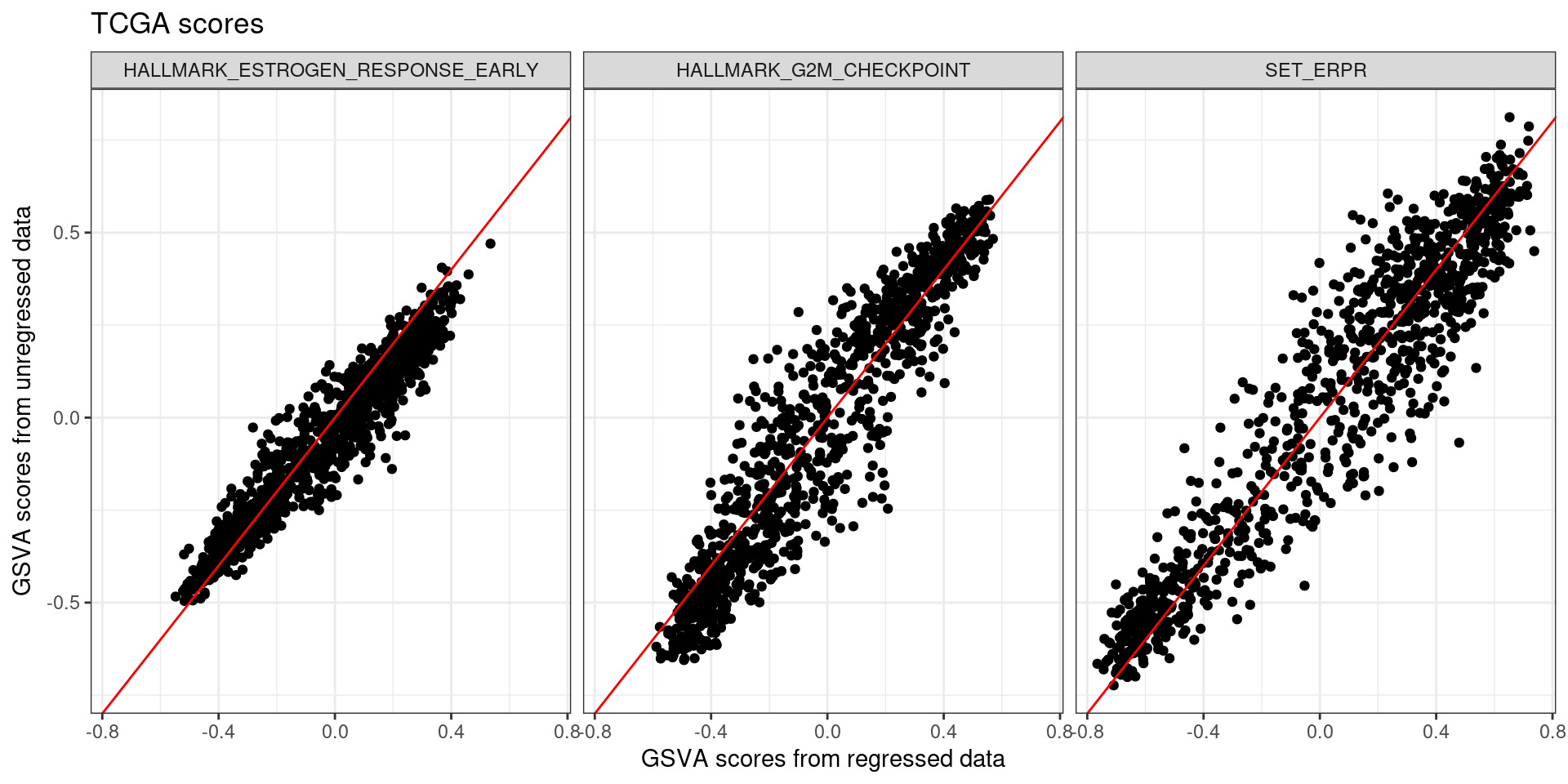
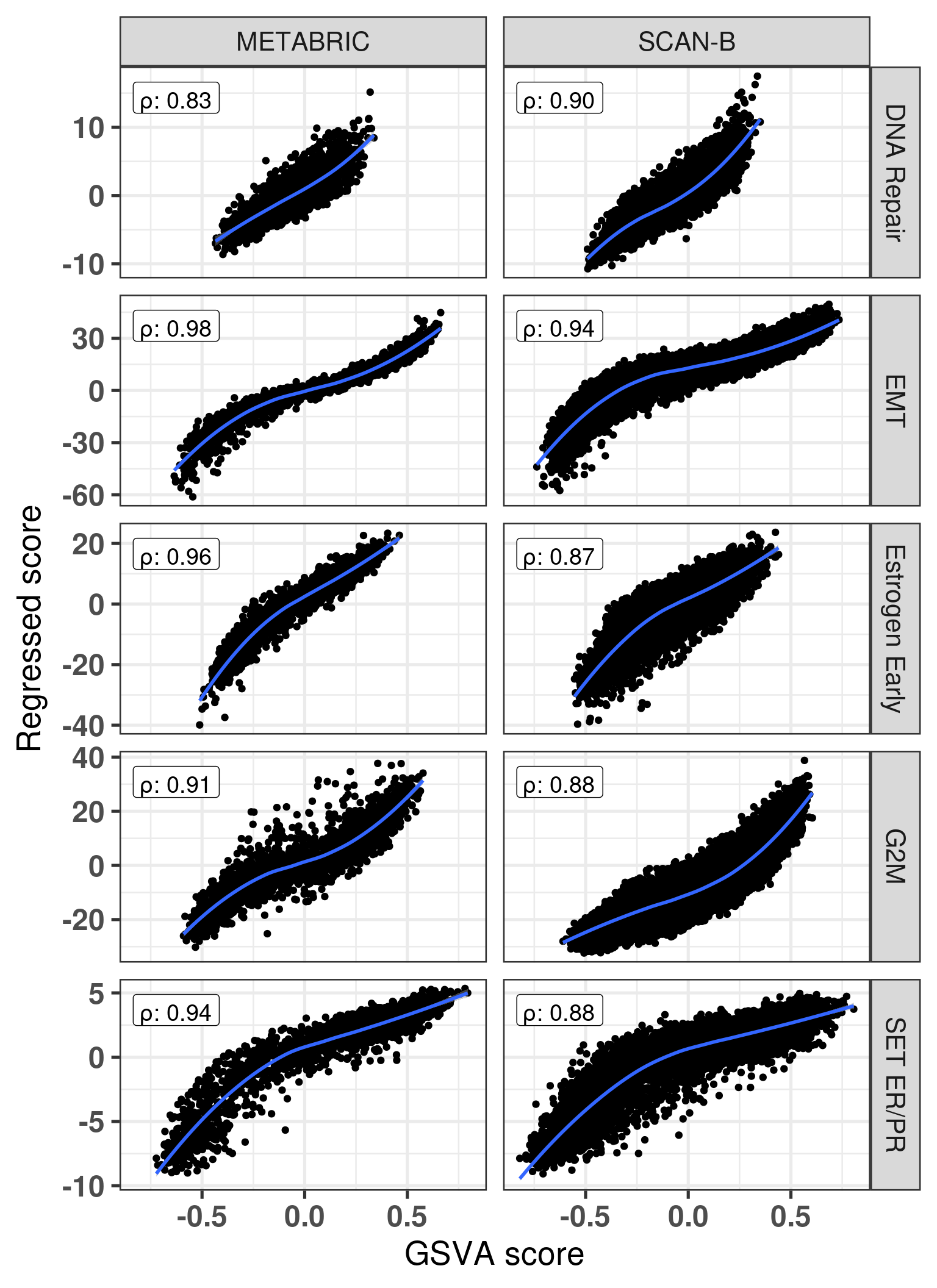
And we can now check and compare the scores.
We see that for the three pathways the correlation is positive and strong. The difference is that it is a bit noisy, so the correlation is not perfect. What is interesting to see is that at the extremes the scores have less variation usually.
We now calculate the scores from SCANB and compare the results. Remember that SCANB was not used for the PCA training.
And we can now check and compare the scores.
The same phenomenon happened. Samples in the endges have lower variability, but samples in the middle are the ones that have high variability. For example there are several samples from the regressed data with SET_ERPR score close to 0.25 and negative scores.
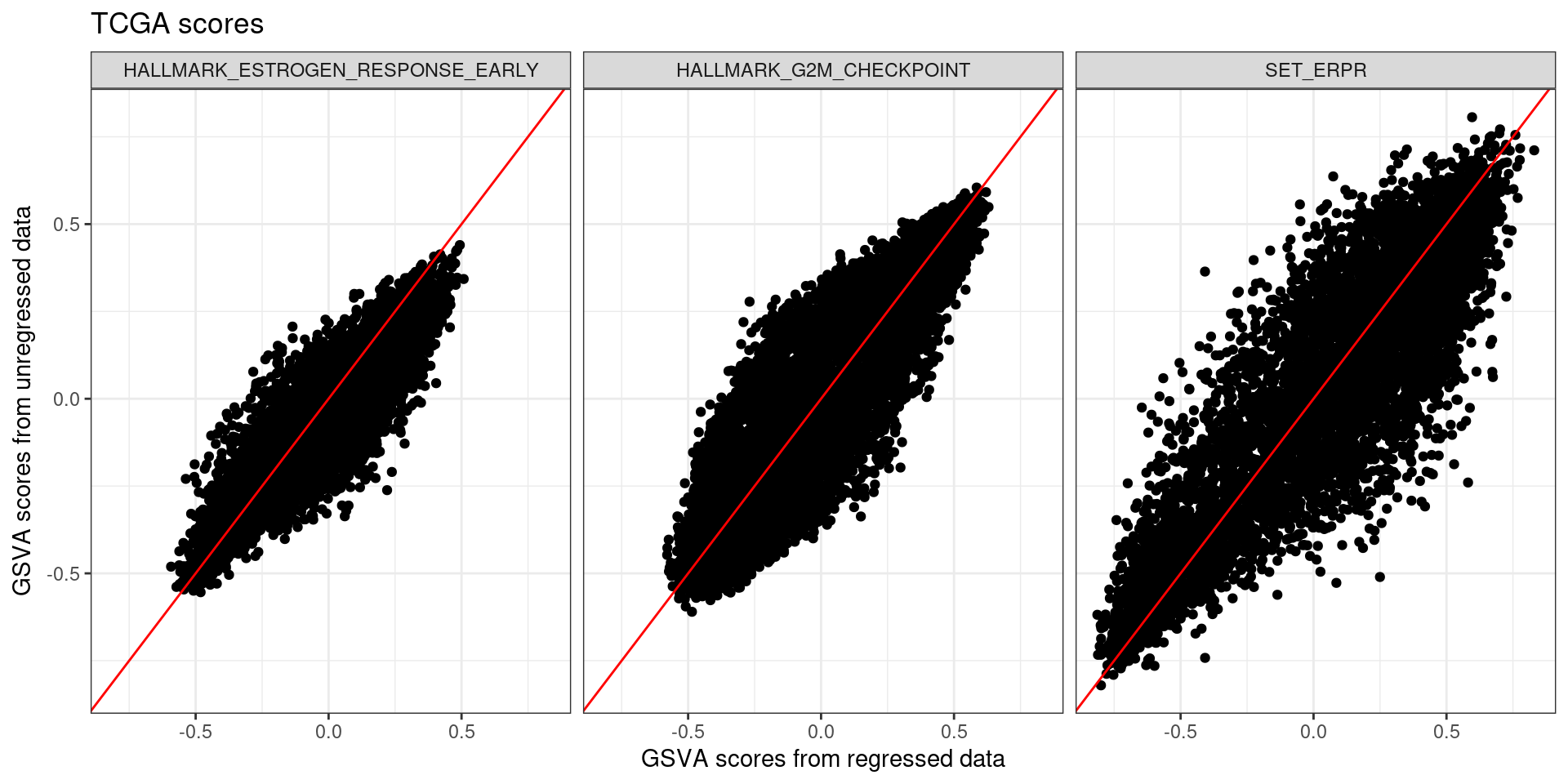
What happens now if we use another dataset and then use only one sample to calculate the score. Let us include SCANB samples in the pipeline. For this we select 50 scanb samples and 100 random samples from tcga and metabric. We then combine all these samples together and calculate the GSVA scores.
We now plot only the scores from the SCANB samples.
So it seems there are still dataset related problems there when calculating the scores. The scores are positively correlated, but they are not quite the same as only using the SCANB dataset. Moreover, for G2M checkpoint the scores are concentrated around -0.4 from the regressed data but they are in a range going from - 0.4 to 0.1 in the unregressed data.
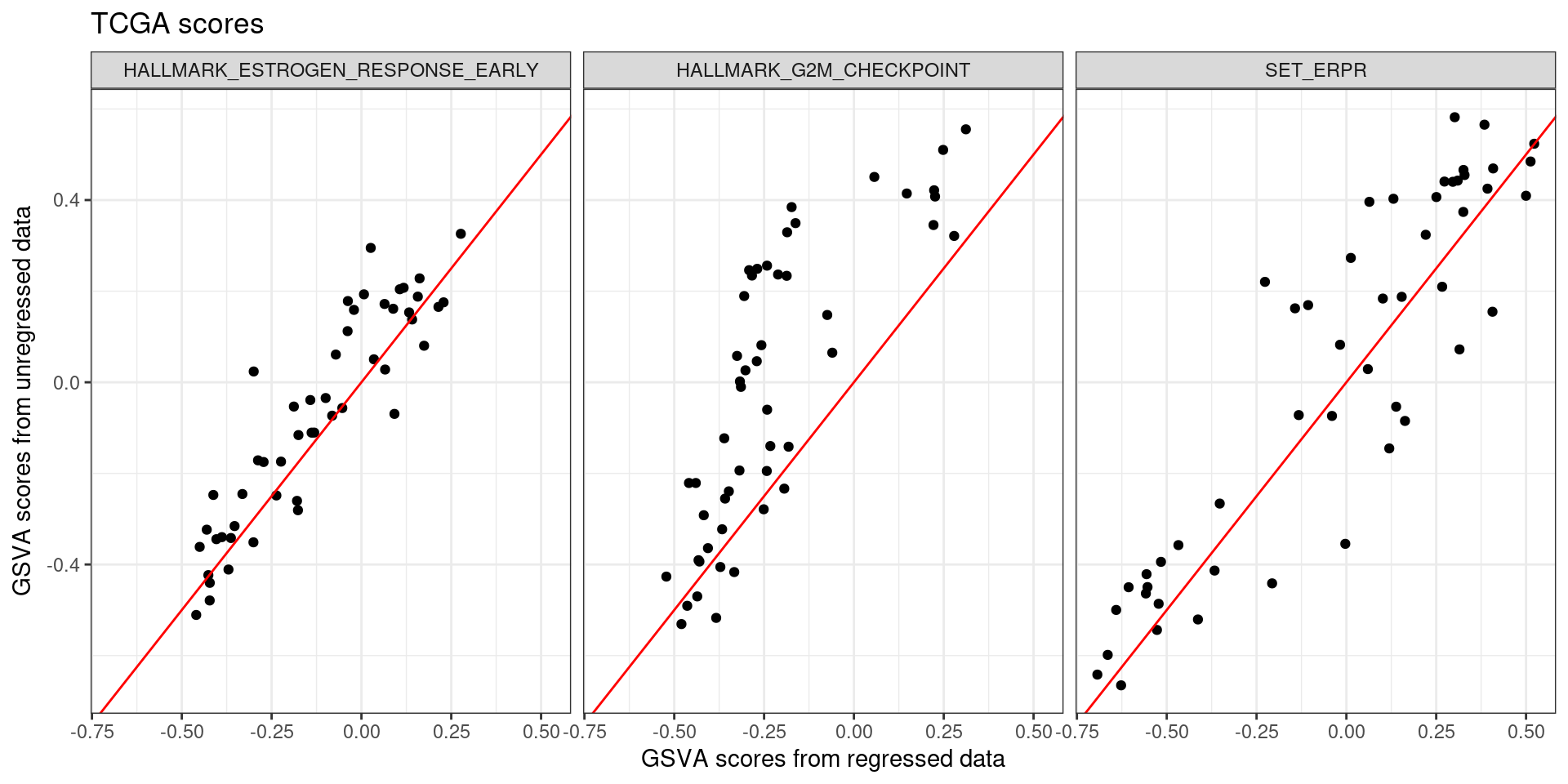
If we try to instead add some samples from the SCANB dataset as well randomly into the mix. How well does the scores get compared to the “ground truth”?
It does not work so well when including some SCANB samples together with the METABRIC and TCGA samples. We are trying to achieve a correlation of almost 1 with very low variability since we want to use the scores clinically.
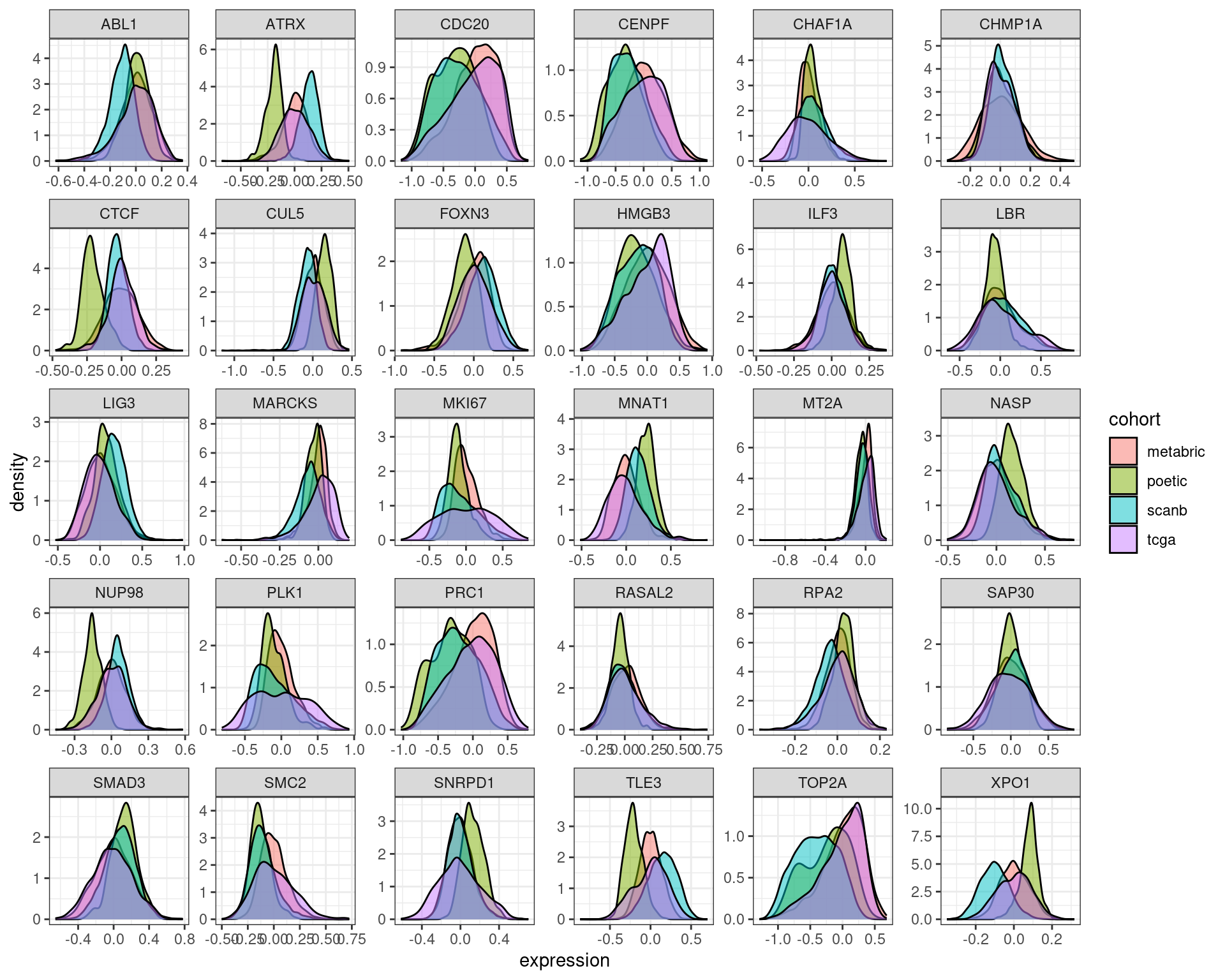
Let us check the distribution of some genes for SCANB and TCGA after regressing out the first two PCs.
We see that even though the expression profile of the samples are overlapping there are discrepancies. That is why when using GSVA it does not work so well perhaps.
6.3 Scoring strategy with regressed data
We now try to use a slightly different scoring strategy. We can think of our data in a log scale, so what we do now instead is to sum all of our genes of interest and then subtract an average of the housekeeping genes expression levels.
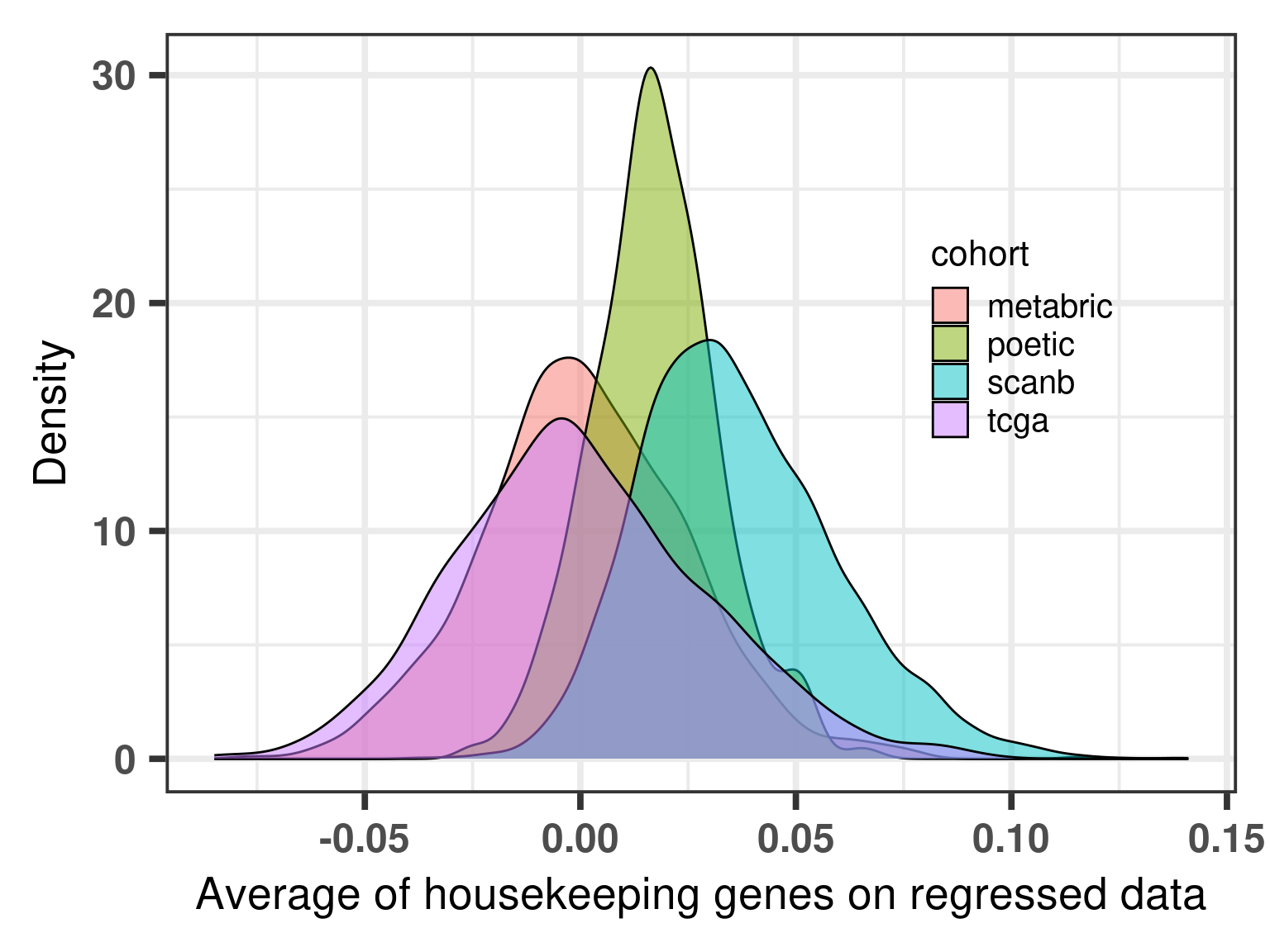
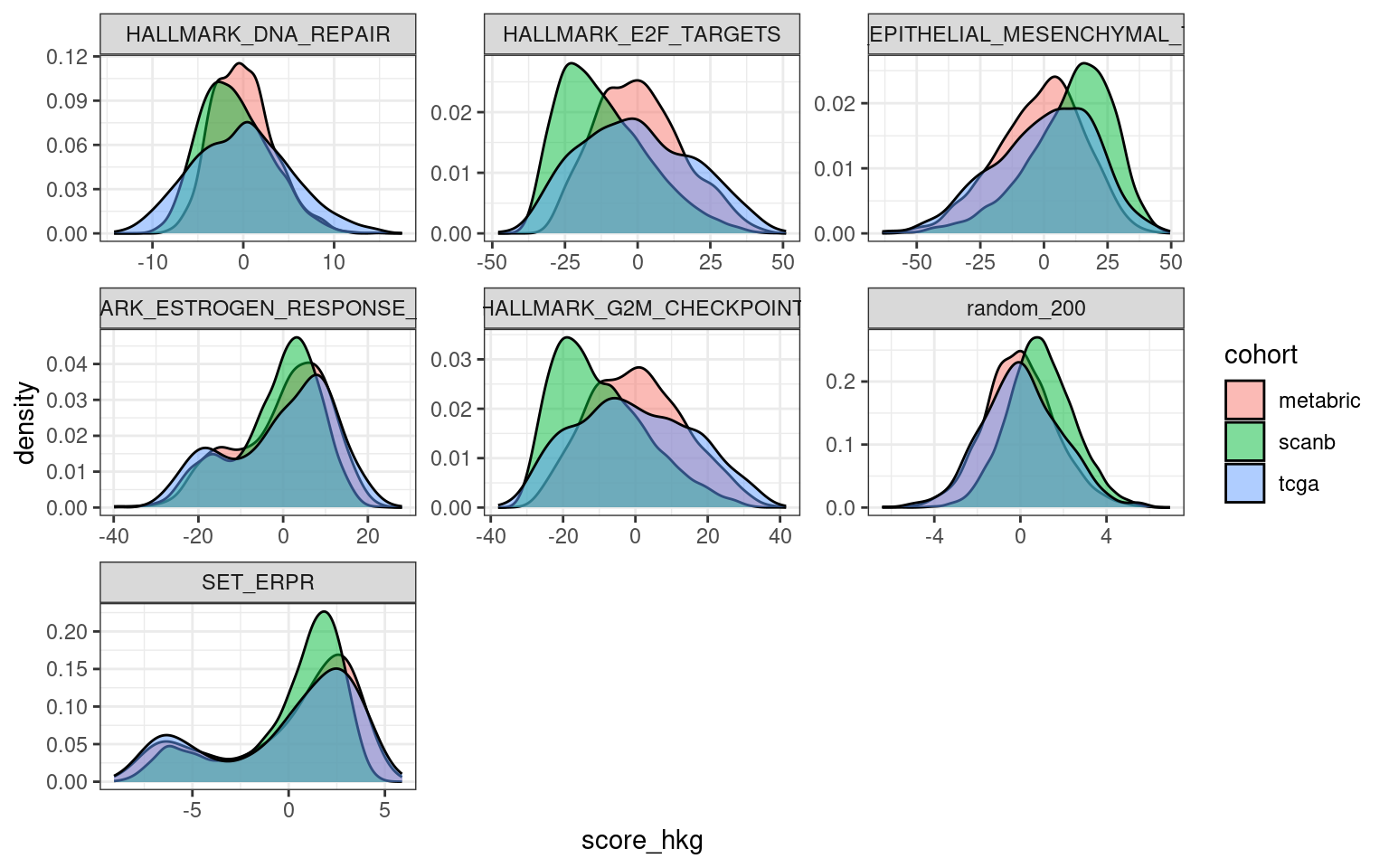
First we check the distribution of this average for each cohort separately.
Figure 6.5: Distribution of the average of the housekeeping genes for distinct cohorts.
Indeed the tcga and metabric cohorts have an overlapping distribution, but the SCANB does not overlap completely, it is actually shifted. One should still take into account that the distributions are very close to 0, meaning that the housekeeping genes have very close to 0 values, as expected here in this case. We now calculate the score by taking this into account.
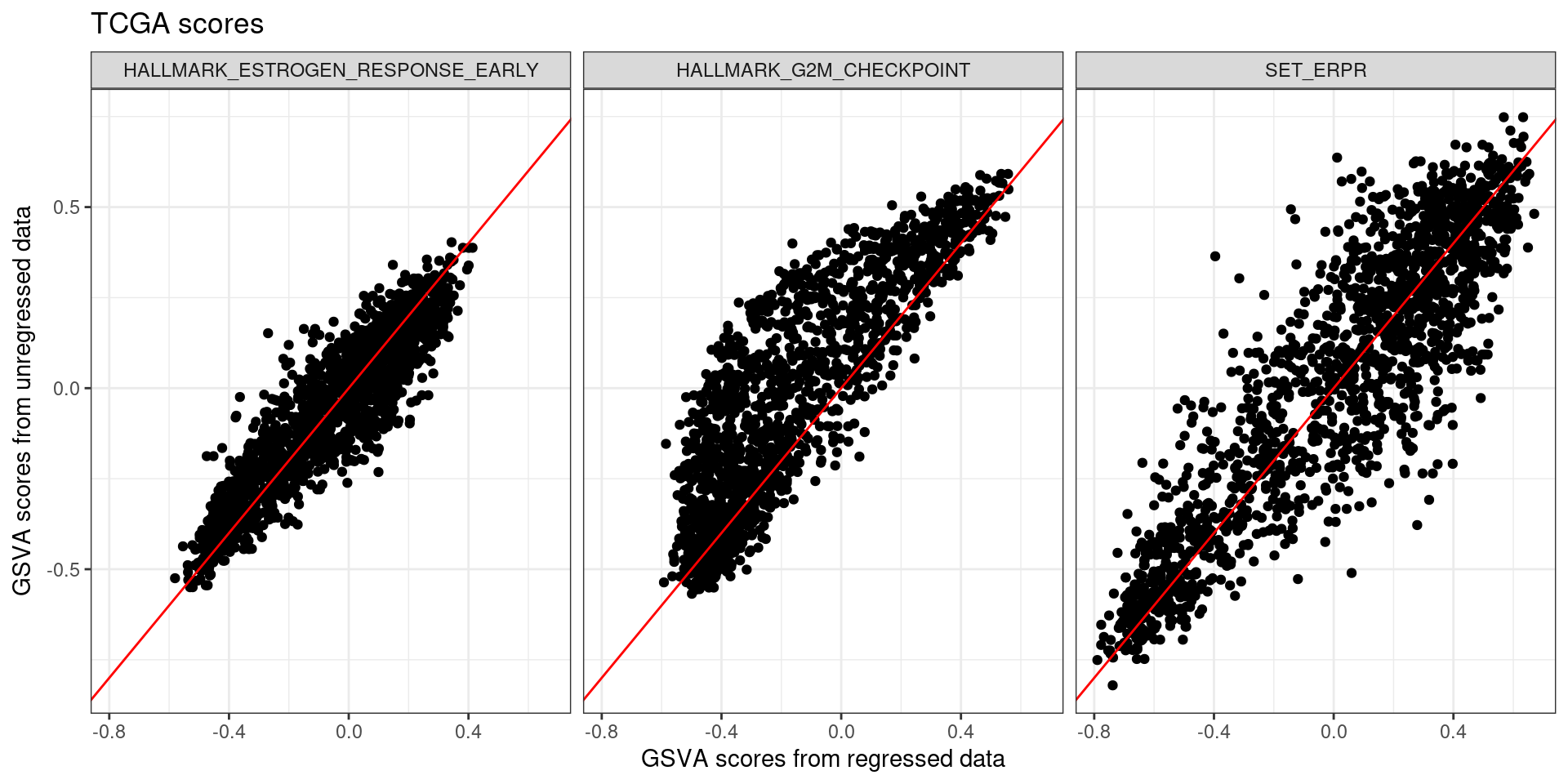
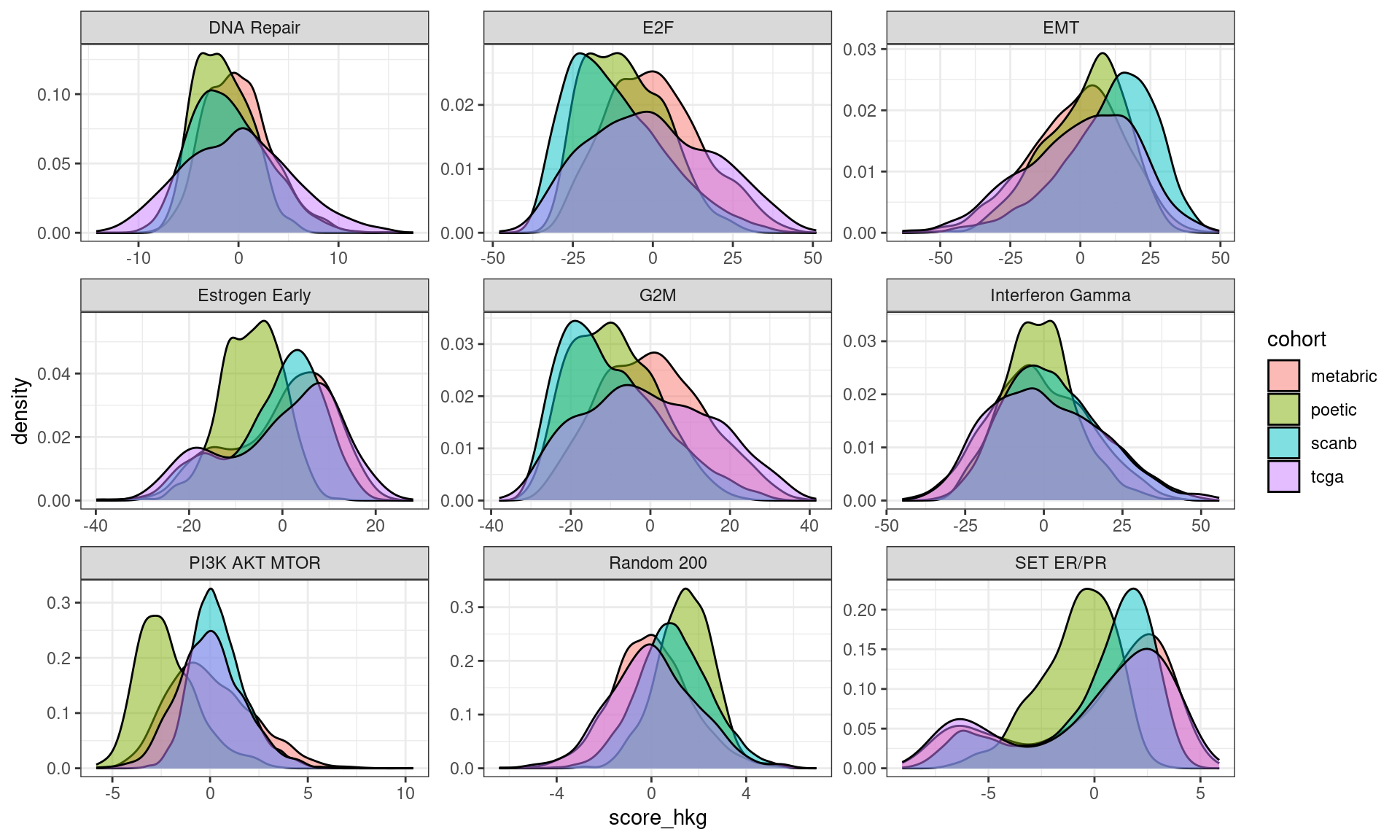
Figure 6.6: Scores obtained from regressed data of all the four cohorts TCGA, SCANB, METABRIC and POETIC compared to the original GSVA scores.
The scores are actually highly correlated, specially the estrogen related pathways. Also the correlation between the scores in general follows the same trends.
The plot below is a subset of the scores above to include in the publication.
Figure 6.7: Scores obtained from regressed data of all the four cohorts TCGA, SCANB, METABRIC and POETIC compared to the original GSVA scores.
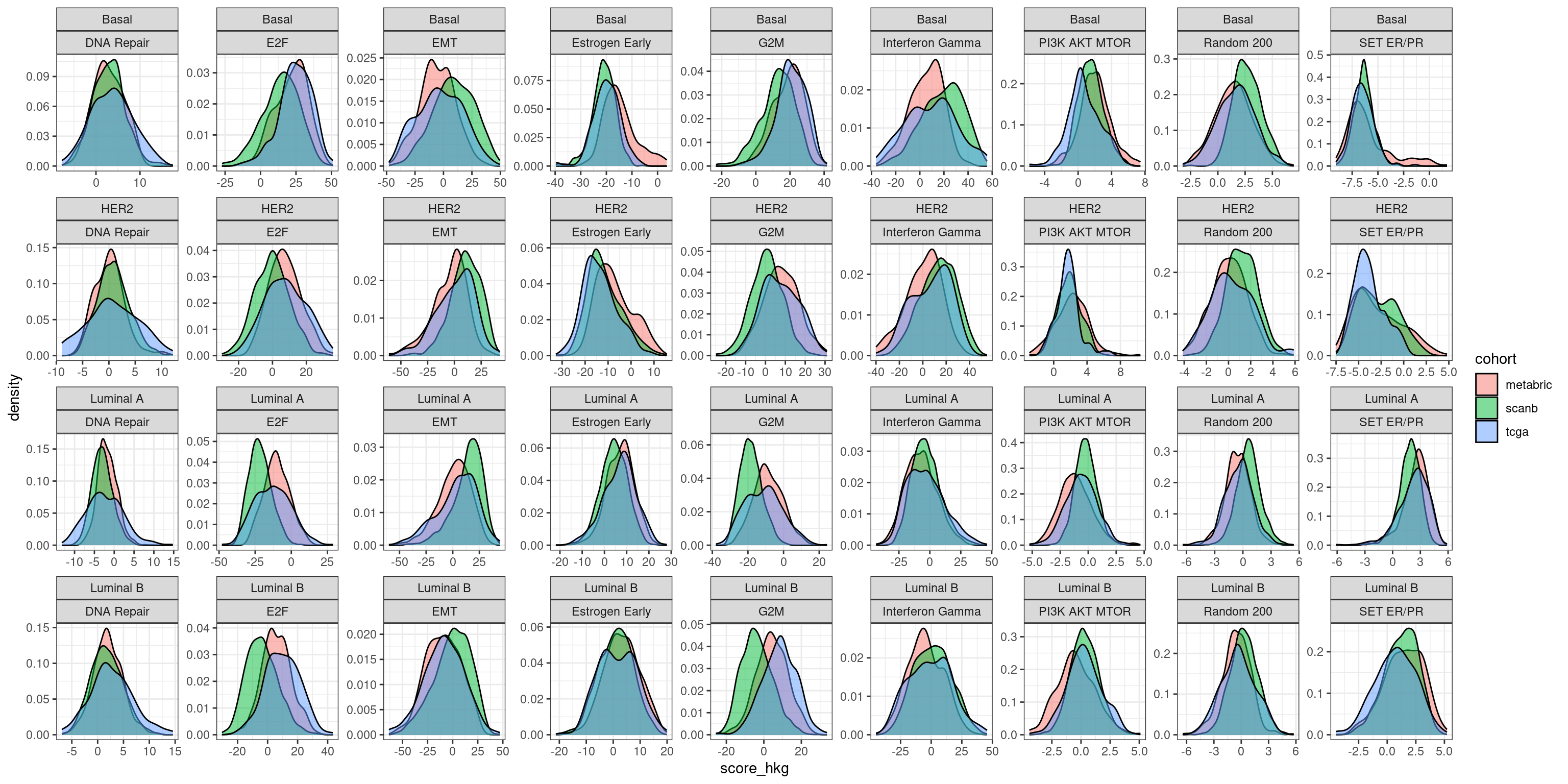
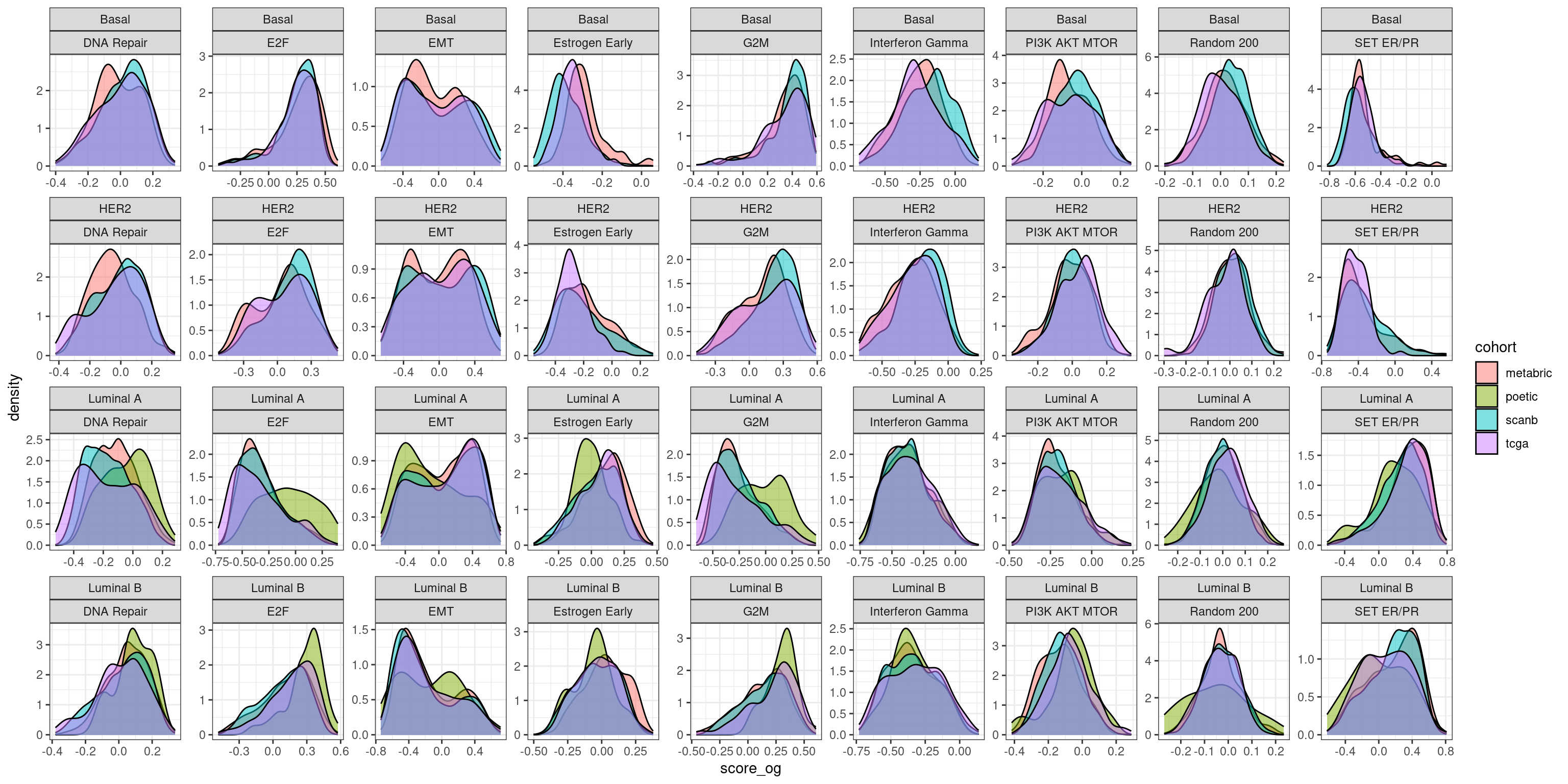
We now compare the distributions of these scores across the different cohorts and pathways of interest.
And with all molecular subtypes together.
We see that the overlap is actually pretty good in general, even for SCANB. The only part where there is a bigger discrepancy is for G2M checkpoint. We see below that by calculating the GSVA score on the whole scanb cohort we don’t have this problem.
And as a comparison we plot with the original scores using GSVA on the whole cohort individually.
And all the subtypes together for the original score:
We see that by doing GSVA the distributions they overlap much more than using the regressed data and the simple sum of the values for those genes. Still for estrogen signaling it seems that the estrogen early signature is pretty robust.
6.3.1 Checking the patients from POETIC with new scores
We now use the new scores to evaluate the comparison with the neighboorhood, just as before in the previous chapter where we used the POETIC trial data.
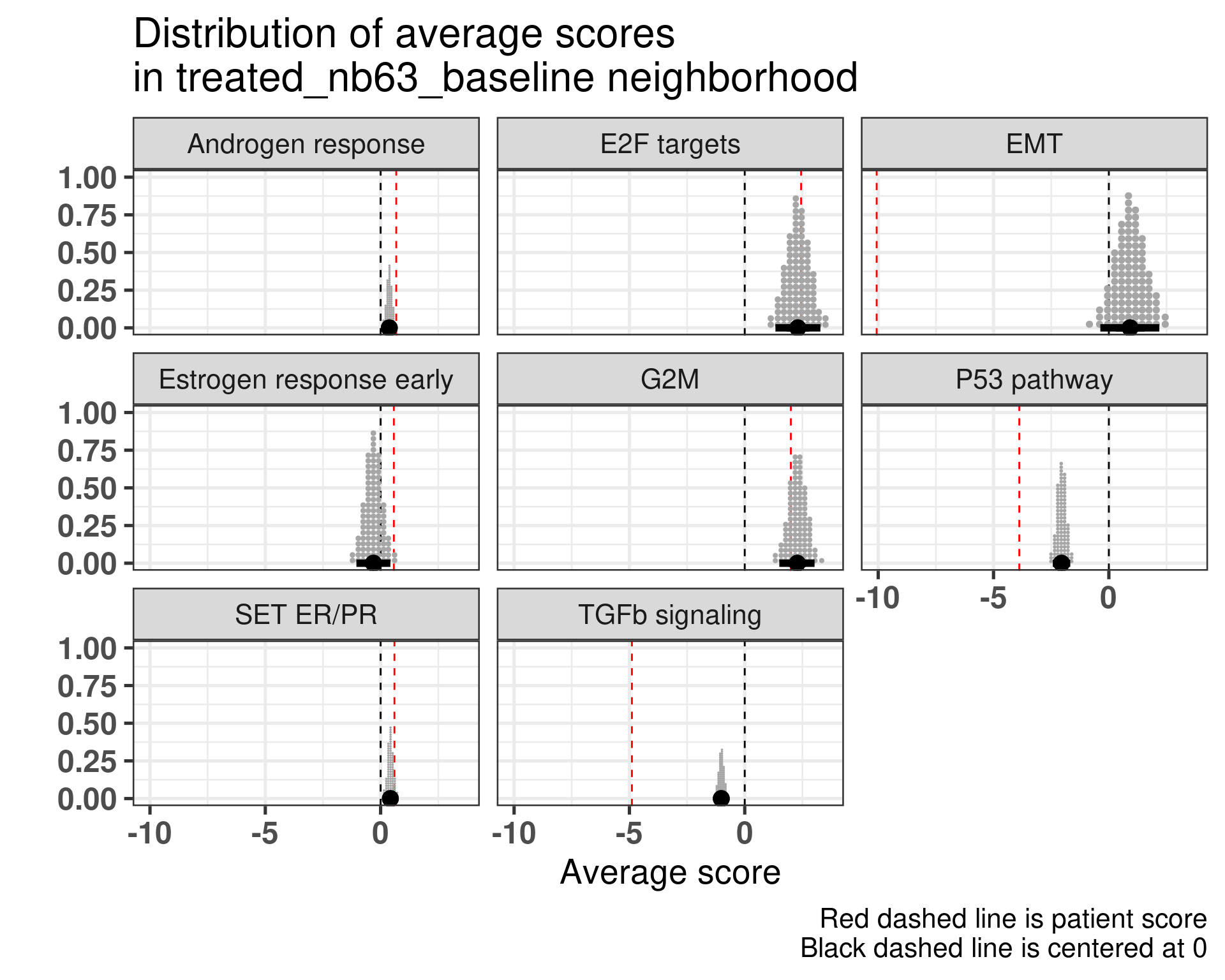
Patient 63 Figure 6.8 is considered a responder. According to the scores, when comparing the estrogen early signature to its average distribution in the neighborhood, the score is higher.
Figure 6.8: Posterior distribution of the average scores in the neighborhood of patient 63 from POETIC trial. Each dot corresponds to a 1% quantile.
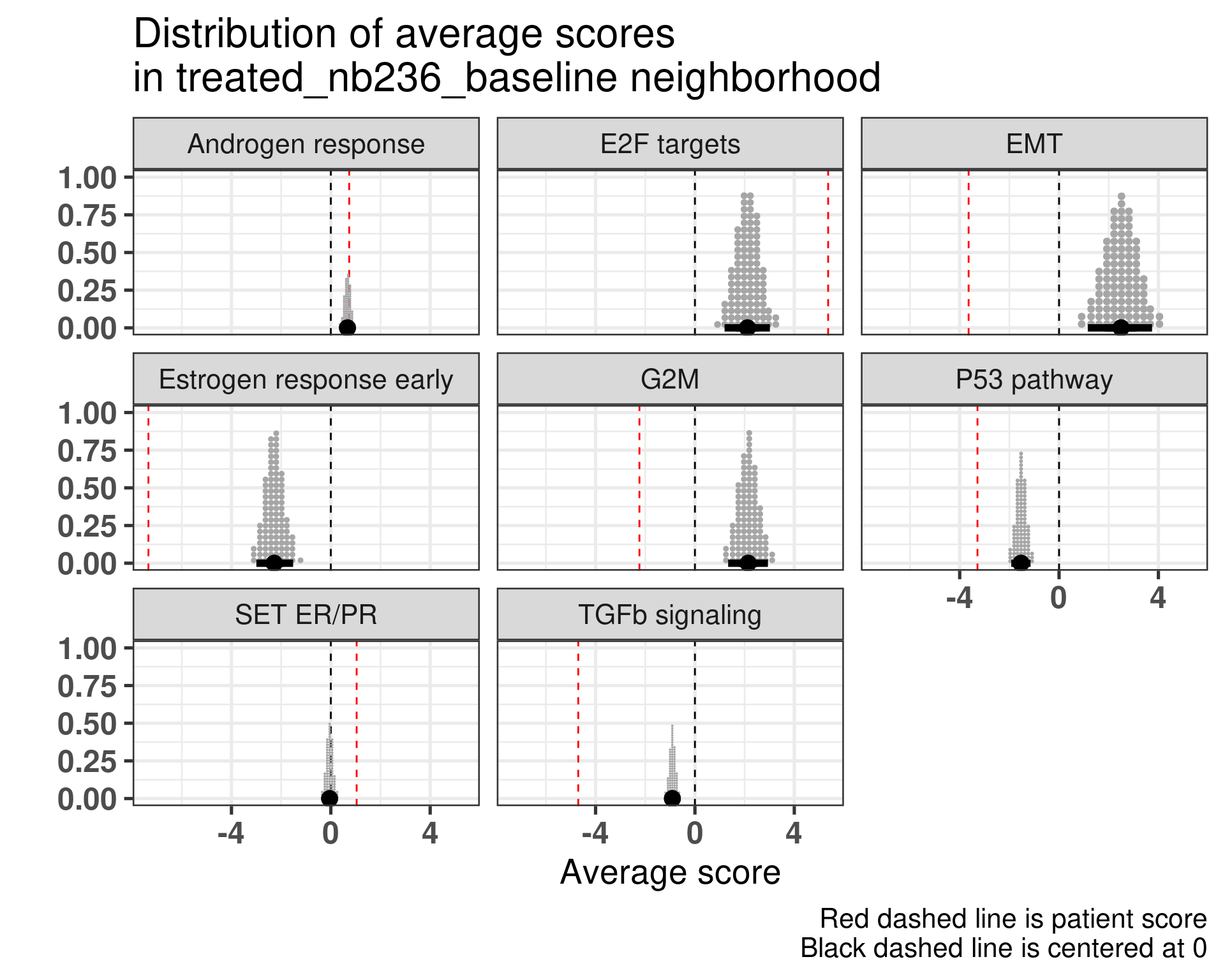
Patient 236 Figure 6.9 was considered a non responder. According to the scores, when comparing the estrogen early signature to its average distribution in the neighborhood, the score is lower, being in the 5% quantile.
Figure 6.9: Posterior distribution of the average scores in the neighborhood of patient 236 from POETIC trial. Each dot corresponds to a 1% quantile.
When comparing these two patients, there is also a difference in the androgen response score, which could be a reflection of different estrogen signaling.
It reflects what we saw previously as well.
6.3.2 Responder vs non responder comparison of new scores
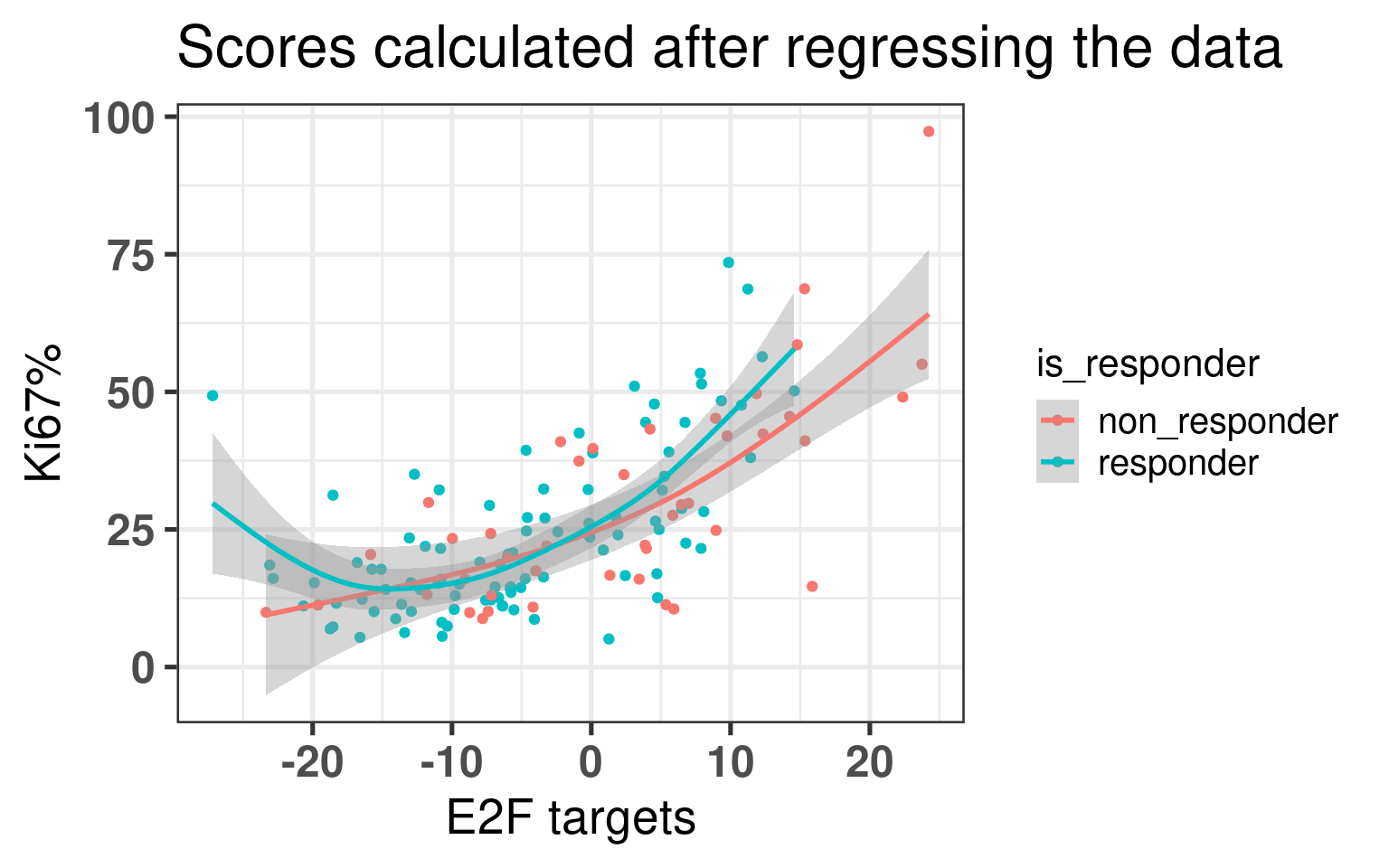
We now compare the scores for responders and non responders.
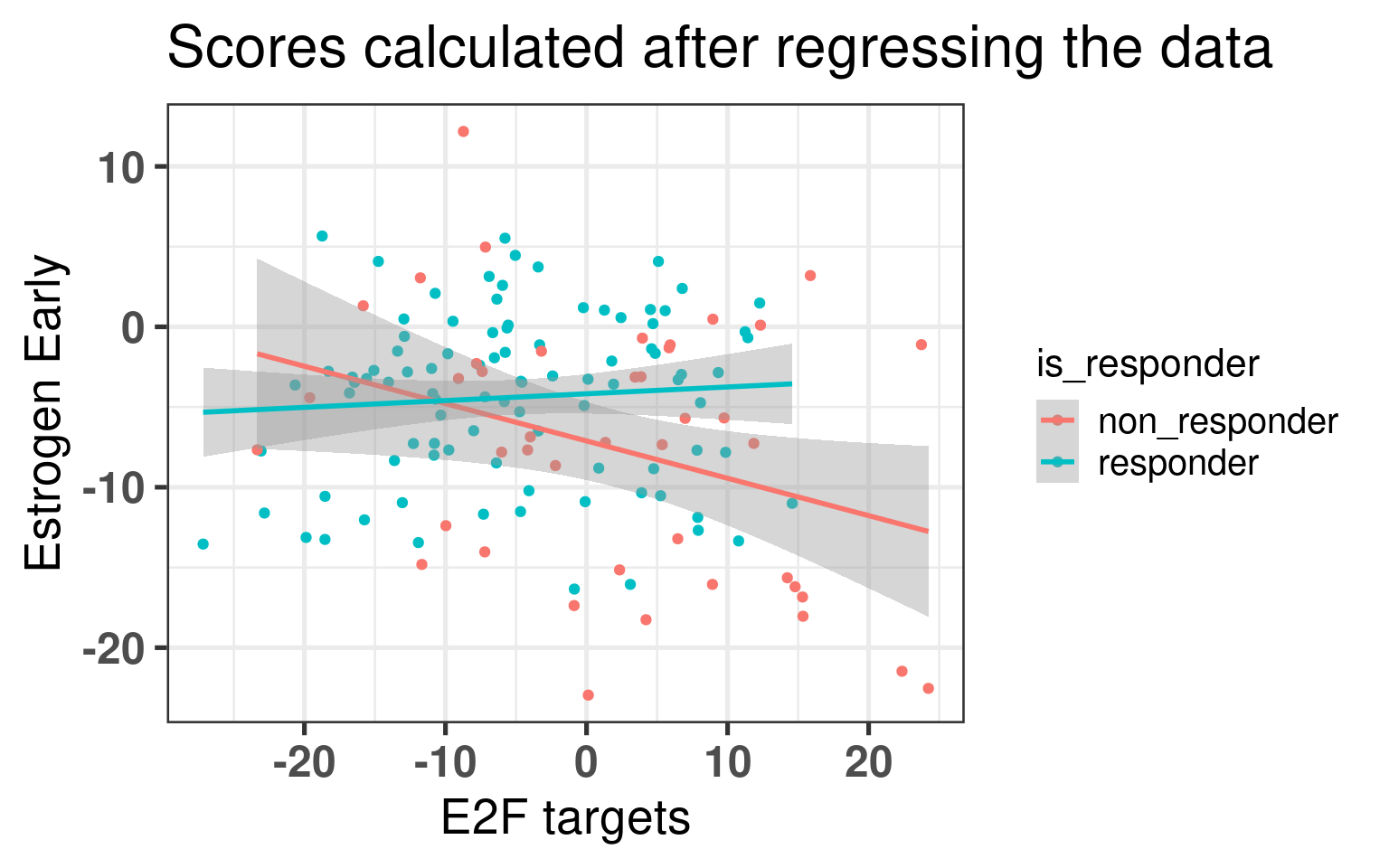
The higher E2F targets in average the lower the estrogen early score is for non responders, whereas this correlation does not exist for responder patients. This difference is mostly drive by the high E2F target non responder tumors.
Now the plot below shows the correlation for baselien Ki67% and E2F targets for the score calculated in the regressed data in a single sample manner. We see a positive correlation between the two scores. Moreover, it is interesting to see that when the tumor has low Ki67, there is still a spectrum on the E2F targets score. Also there is no difference in the correlation between responders and non responders.
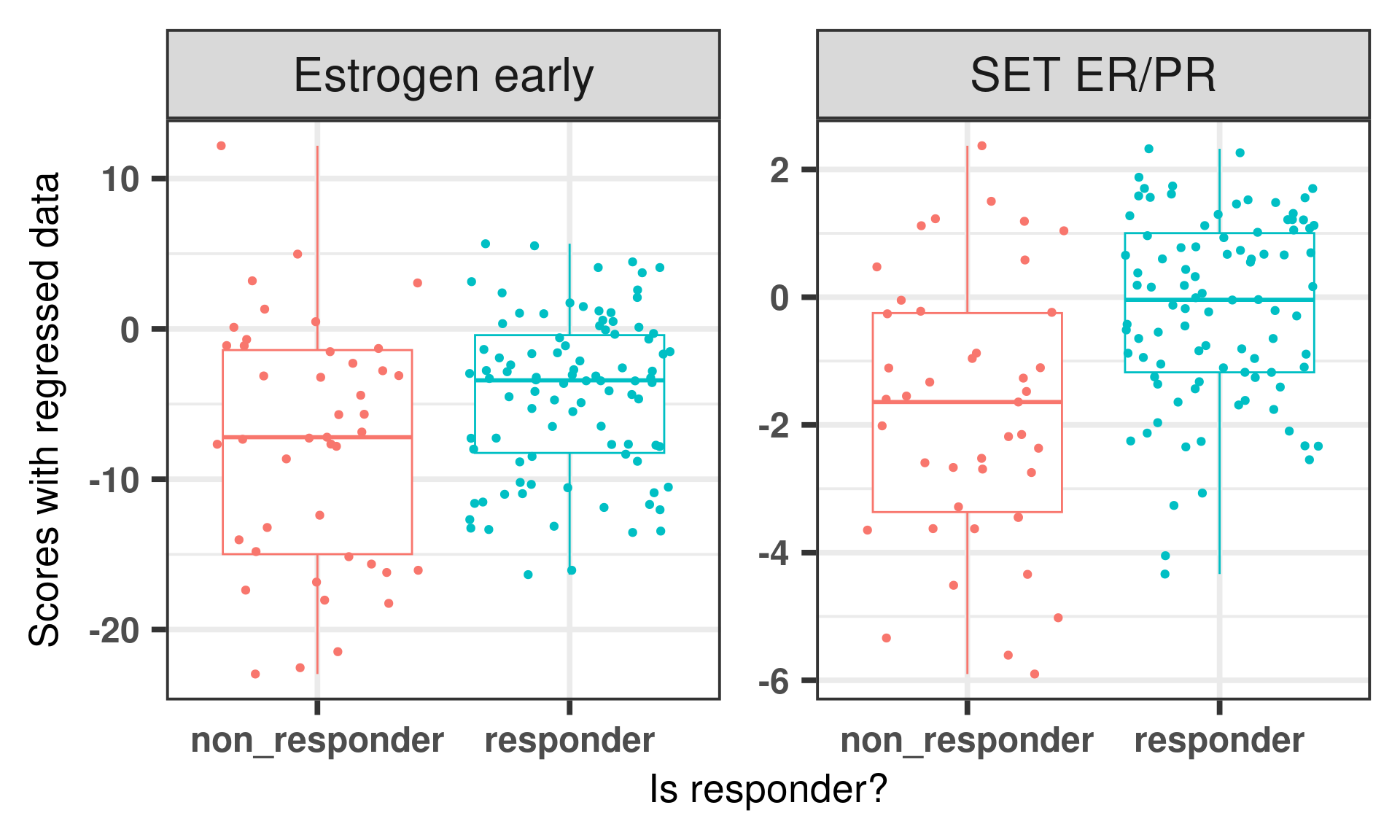
And lastly we compare the estrogen signaling signatures between responders and non-responder.
We see that the estrogen response early has a wider range when compared to the SET ER/PR score. That makes sense as this signature has over 100 genes, whereas SET ER/PR has only 18. Also the responder was very good in discriminating the responders and non responders. What we can conclude from this figure is that the samples with very low scores are usually non responders, which reflect their position in the molecular landscape, also in general responders have higher ER signaling than non responders.
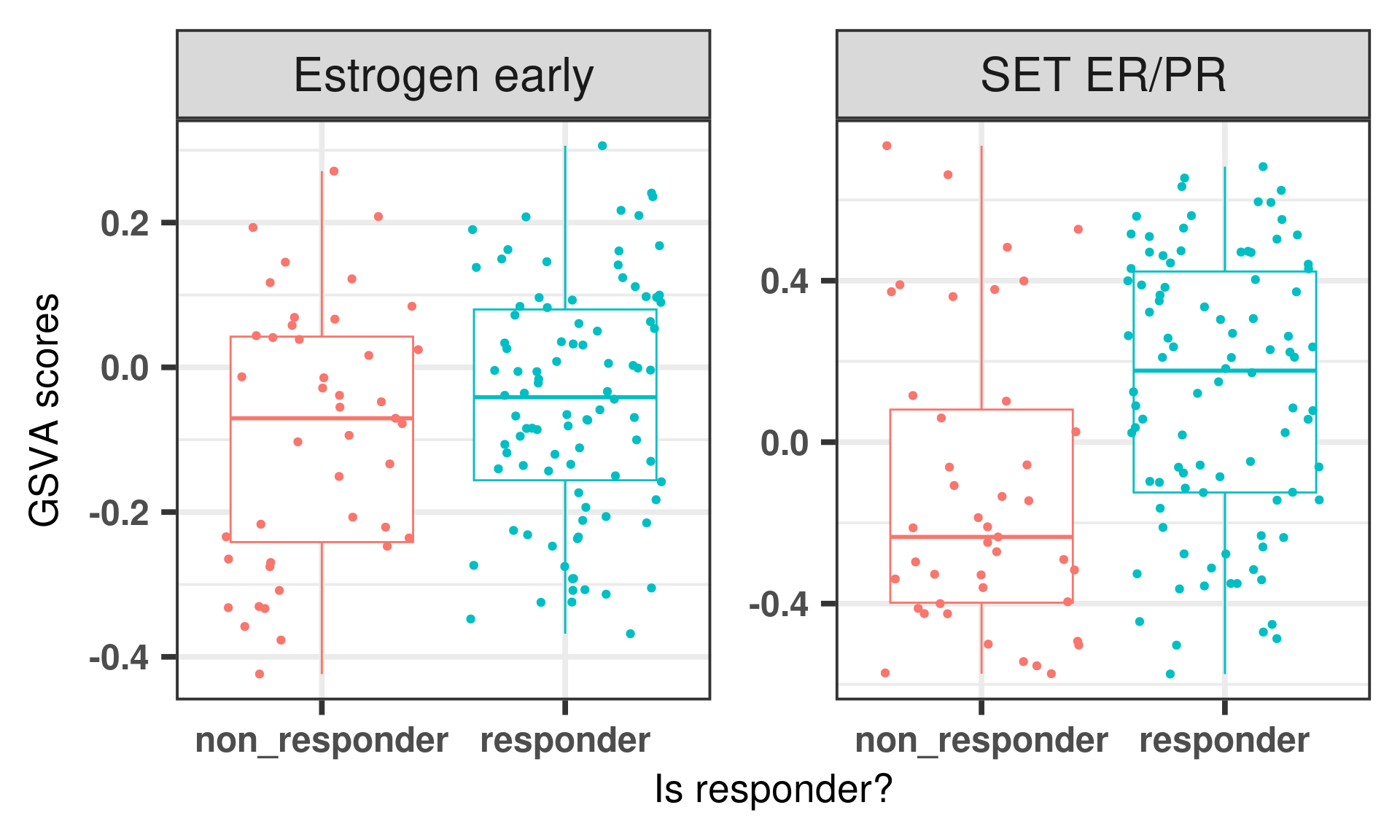
Below is the figure with the GSVA scores before regressing the data, we see that SET ER/PR is not able to really distinguish completely the non-responders with very low score similar to what was done with GSVA. Even estrogen early had some differences.
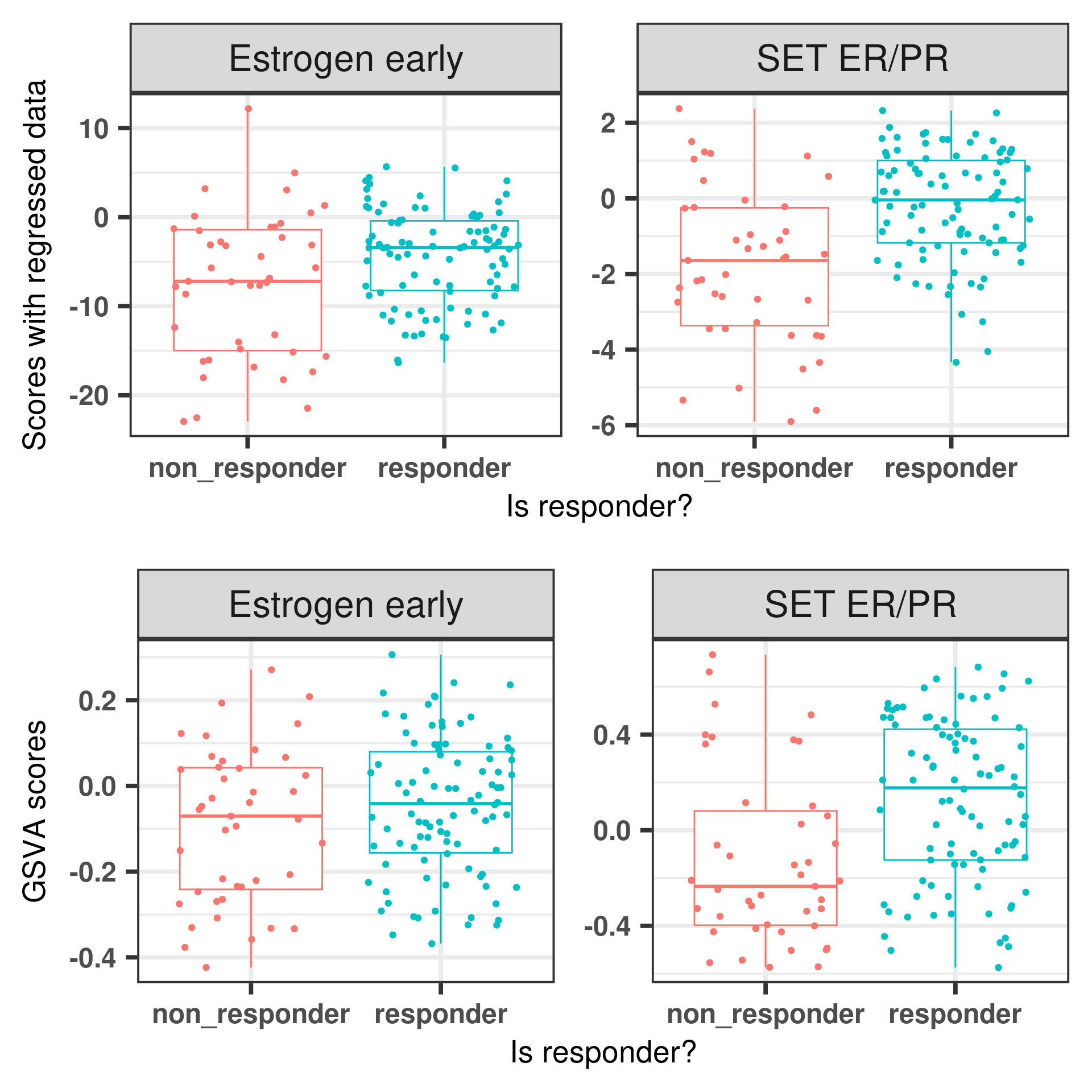
And below is a figure with both GSVA and regressed scores together.
Figure 6.10: Comparing scoring strategies for responders and non responders in the POETIC dataset.
Below we show the correlation between these scores for all cohorts.
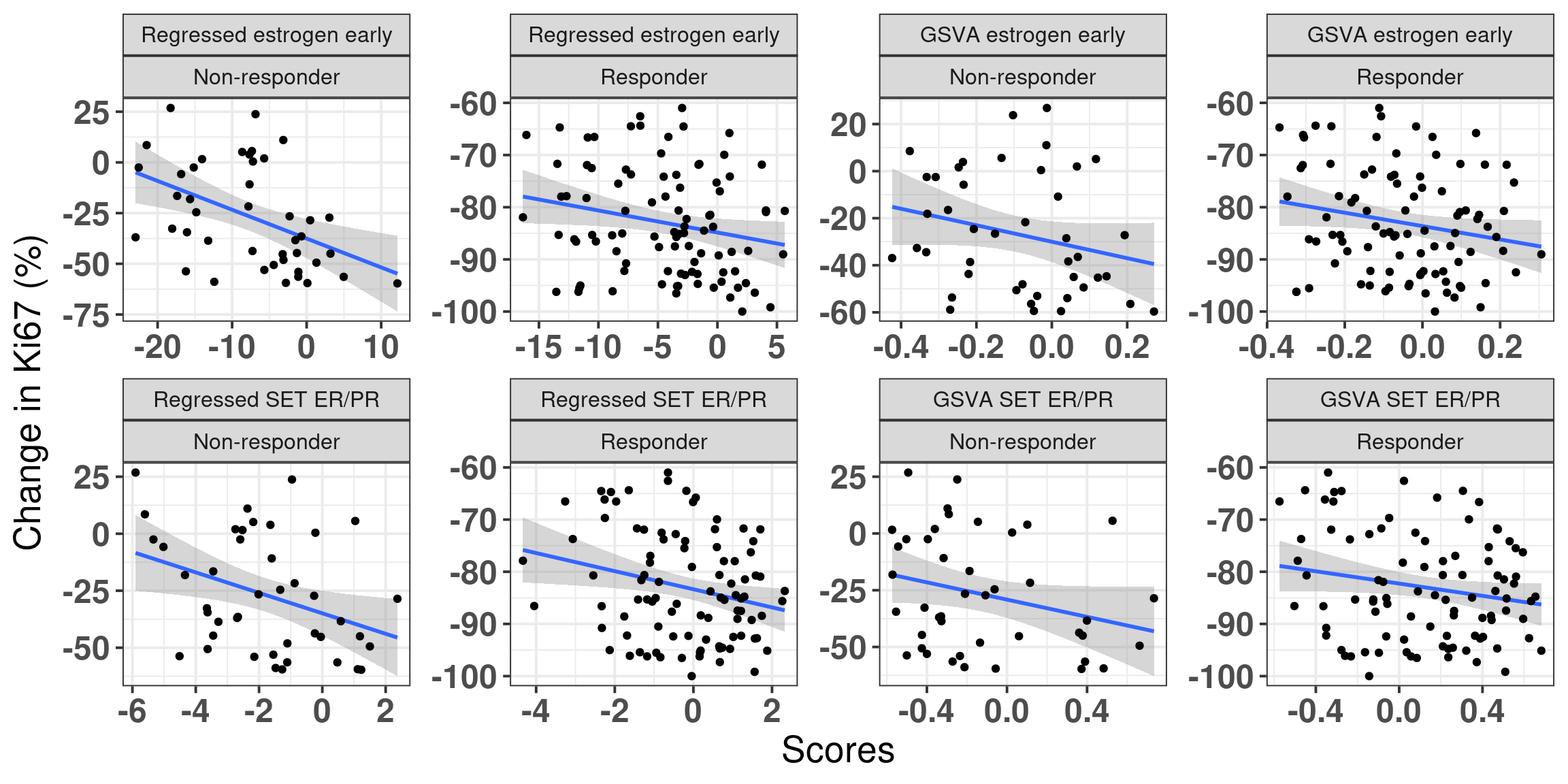
These scores are highly correlated but in different absolute scales. We now check the change in Ki67 for all patients and compare the scores with the original ones obtained with GSVA.
Figure 6.11: Comparison of original GSVA and regressed scores between responders and non responders compared to change in Ki67.
We see that the bigger the change the higher the score is when using the regressed data. Also the non responders tend to have scores mostly in the negative scale, whereas the responders are more shifted to the right. SET ER/PR is also a good measure here.
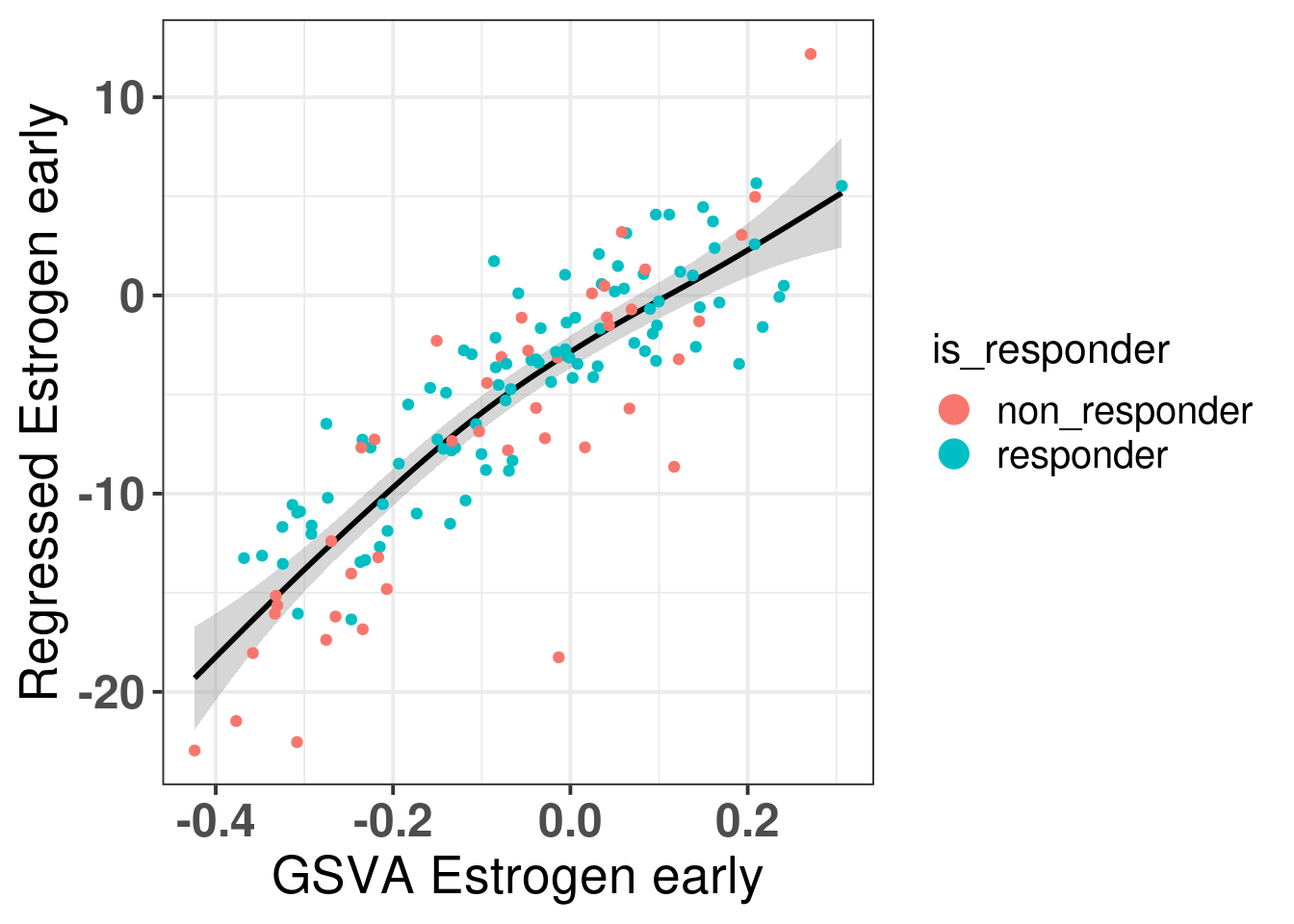
There is a very good match between the two scores in general, meaning that the regression scoring strategy capture relatively well the scores. There is one patient that is a non-responder and has a low regressed estrogen early but a GSVA score close to 0, let us check this patient.
It is a patient that is far to the left on the molecular landscape, among the basal like, and had an increase in Ki67 upon ET. So the new scoring system was able to capture this patient as with low score.
6.3.3 Survival analysis with the new scores
We can check how robust these scores are by performing survival analysis.
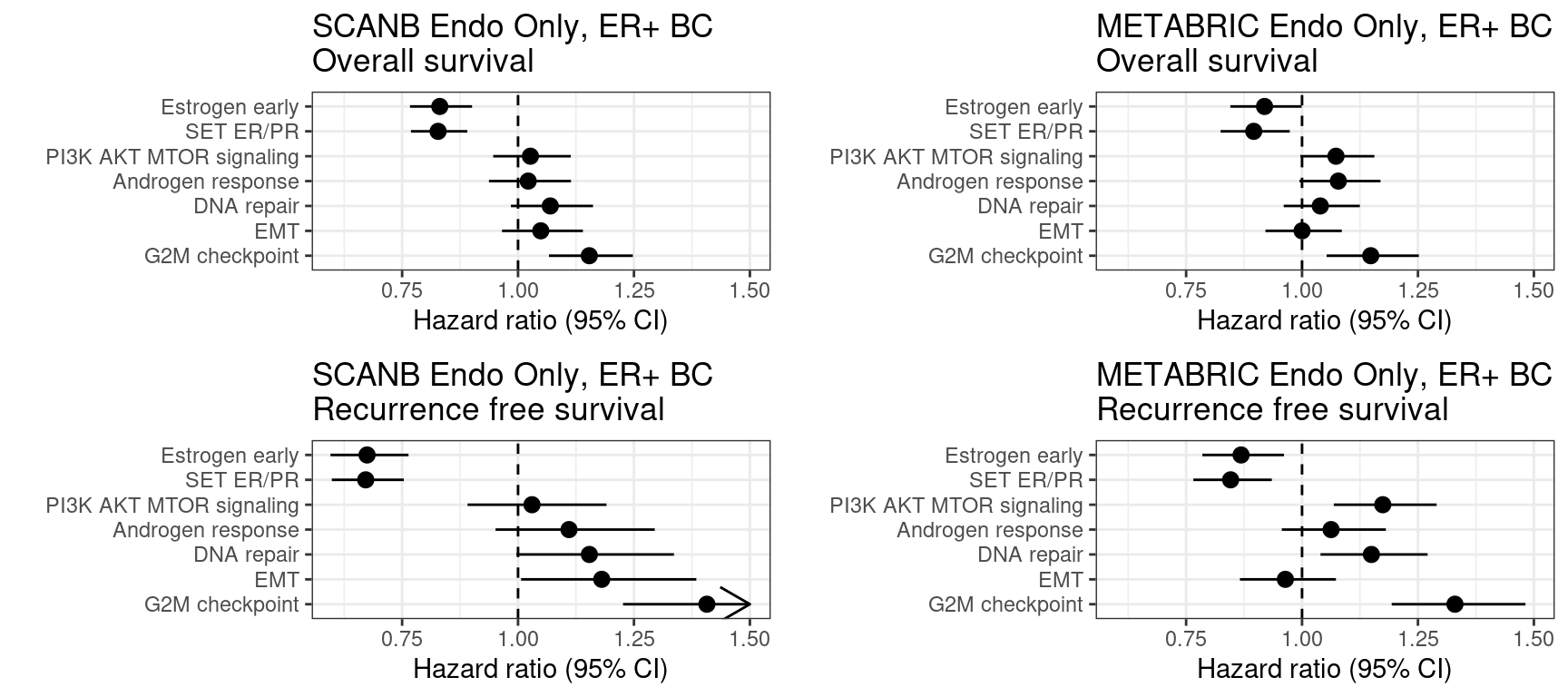
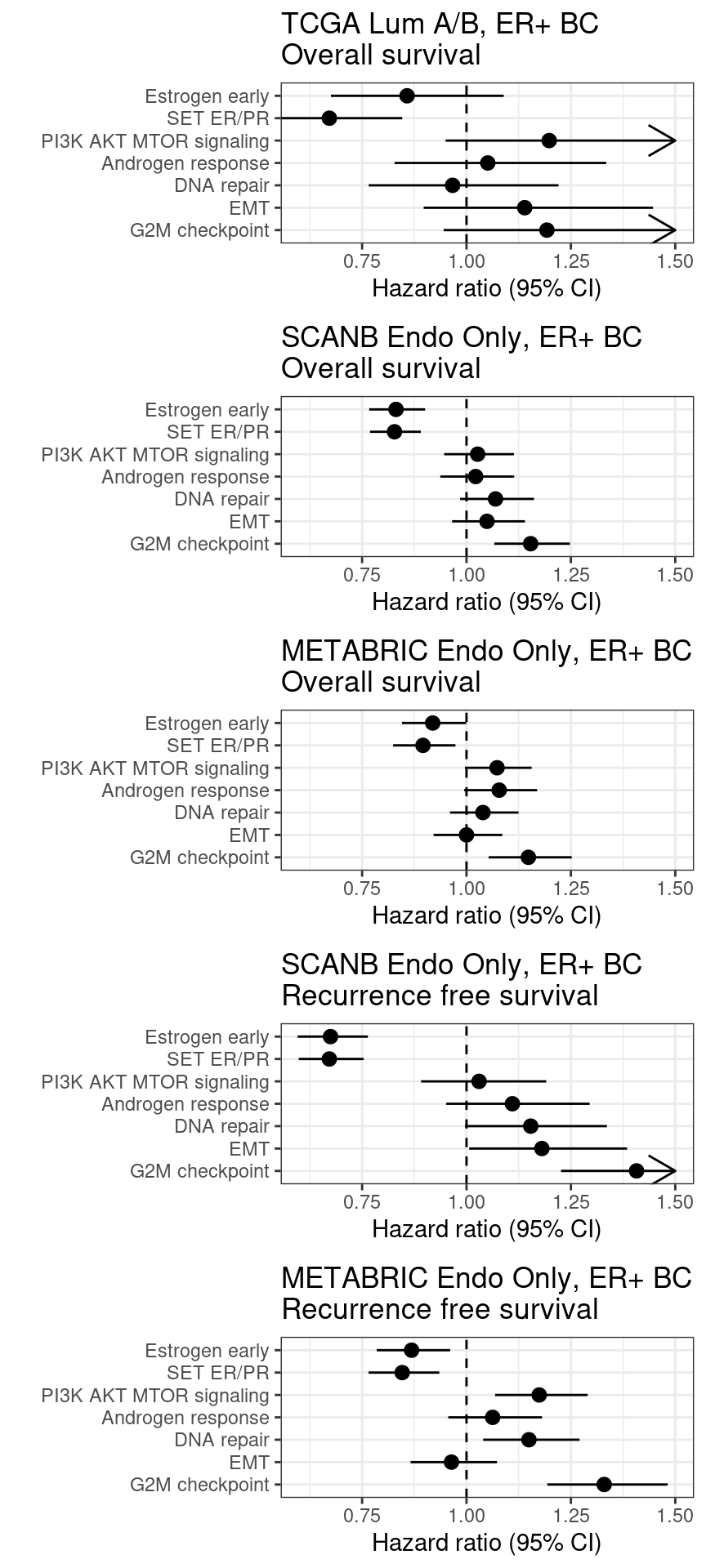
Figure 6.12: Overall survival analysis from SCANB and METABRIC cohorts and their scores. The formulas used were the same as for the estrogen signaling analysis. Coefficients were scaled before performing cox regression
The plot with TCGA is shown below.
Scores for TCGA are noisier than SCANB and METABRIC. Though the scaled scores they have comparable hazard ratios and also they follow what we saw previously. The only pathway that is a bit different is the PI3K AKT MTOR signaling. This pathway had a noisier correlation with the GSVA score as well.
6.4 Regressing the PDXs
We can use the regressing strategy to score the PDXs and then evaluate their scores.
Total number of stable genes: 39
Total number of genes: 8205
Number of samples: 76
[1] "Normalization done."
We start by comparing the scores across the different control samples and their positions in the molecular landscape.
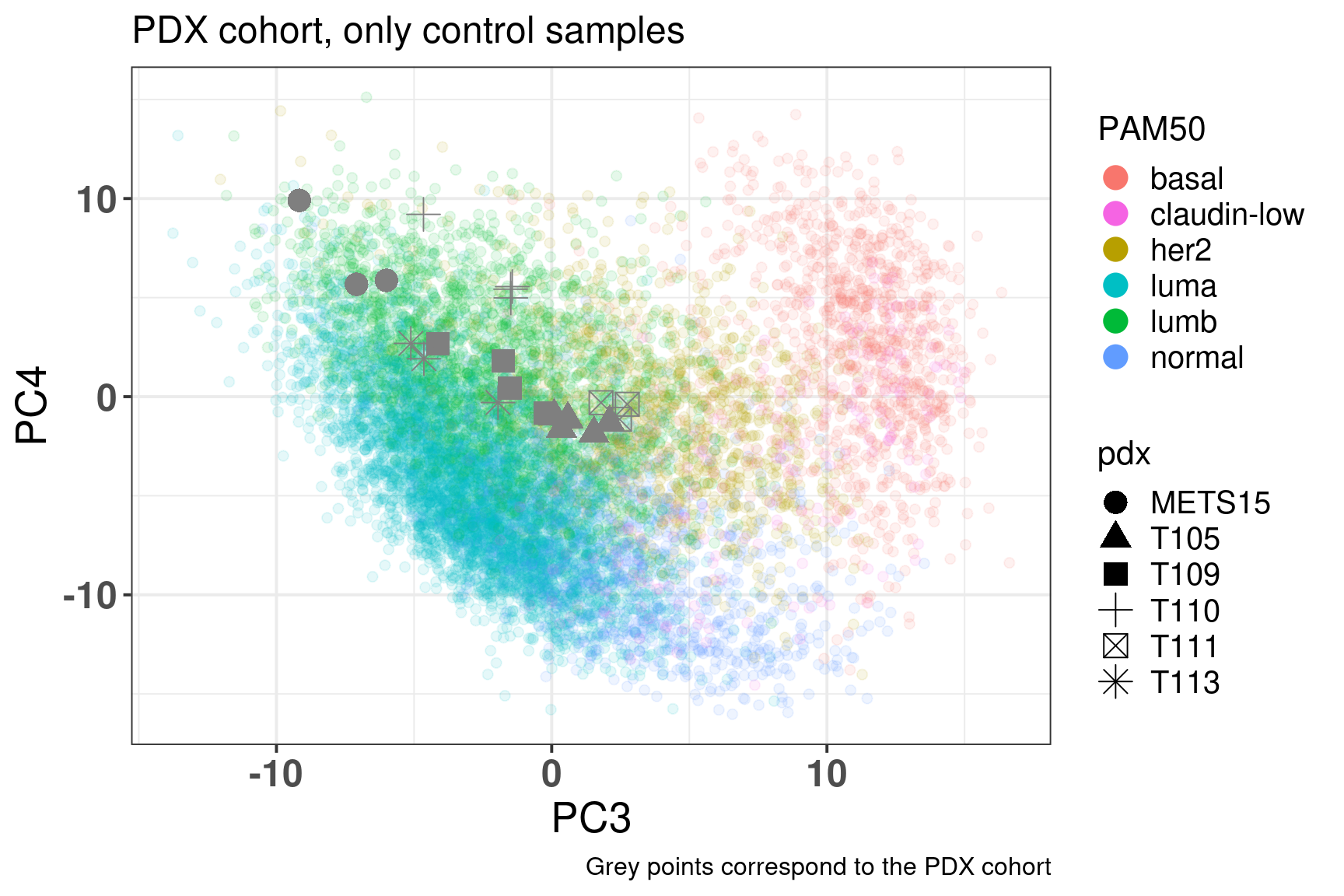
Figure 6.13: Embedding of only regressed PDX control samples on top of the METABRIC, SCANB and TCGA samples
The results are jus twhat we got previously as well, meaning that by using all these genes the information of the PDXs are still captured. The main differences is that the luminal B region is more compact compare to Figure 3.20.
And now that we have the results we can compare the PDXs as well.
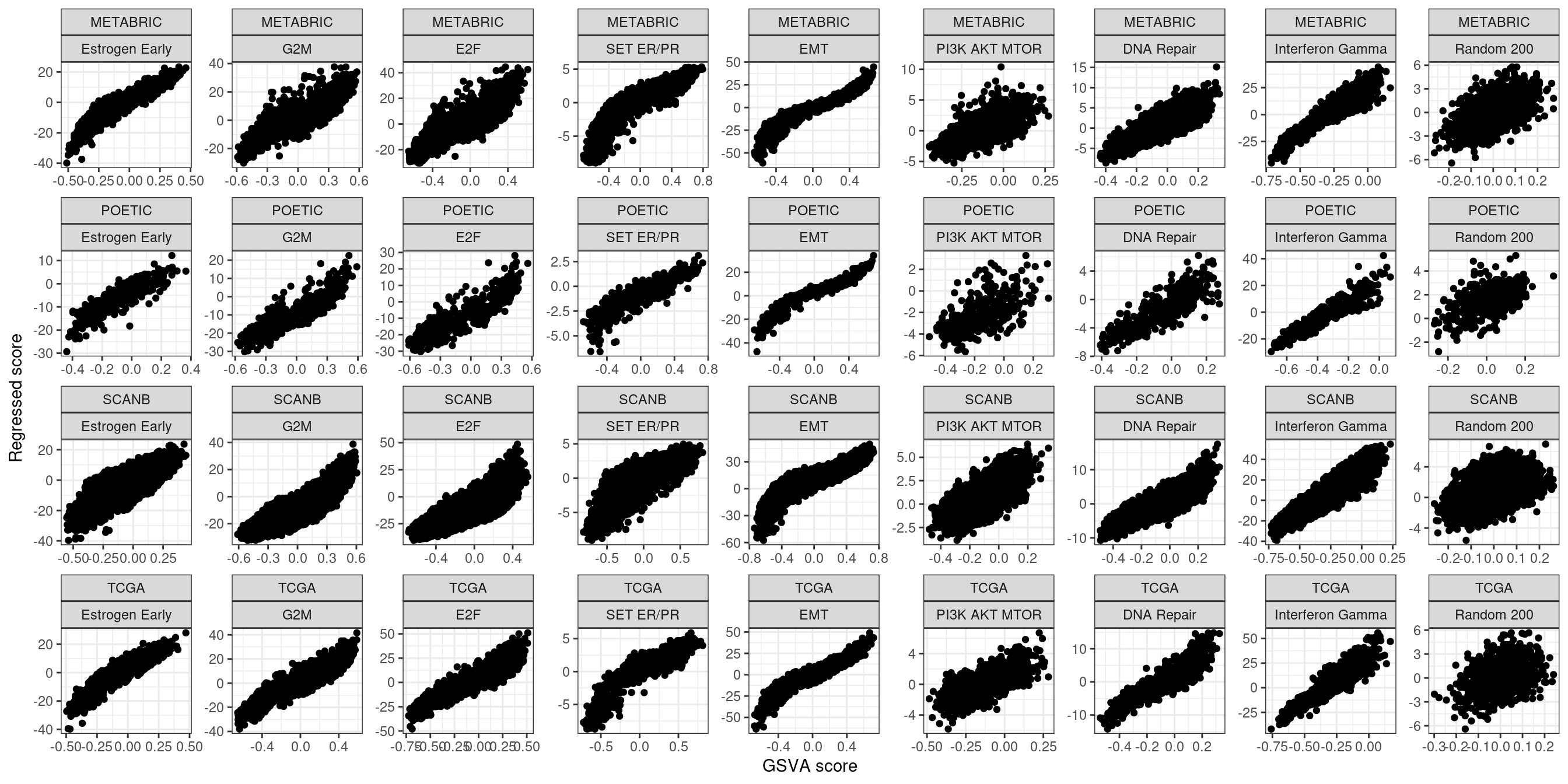
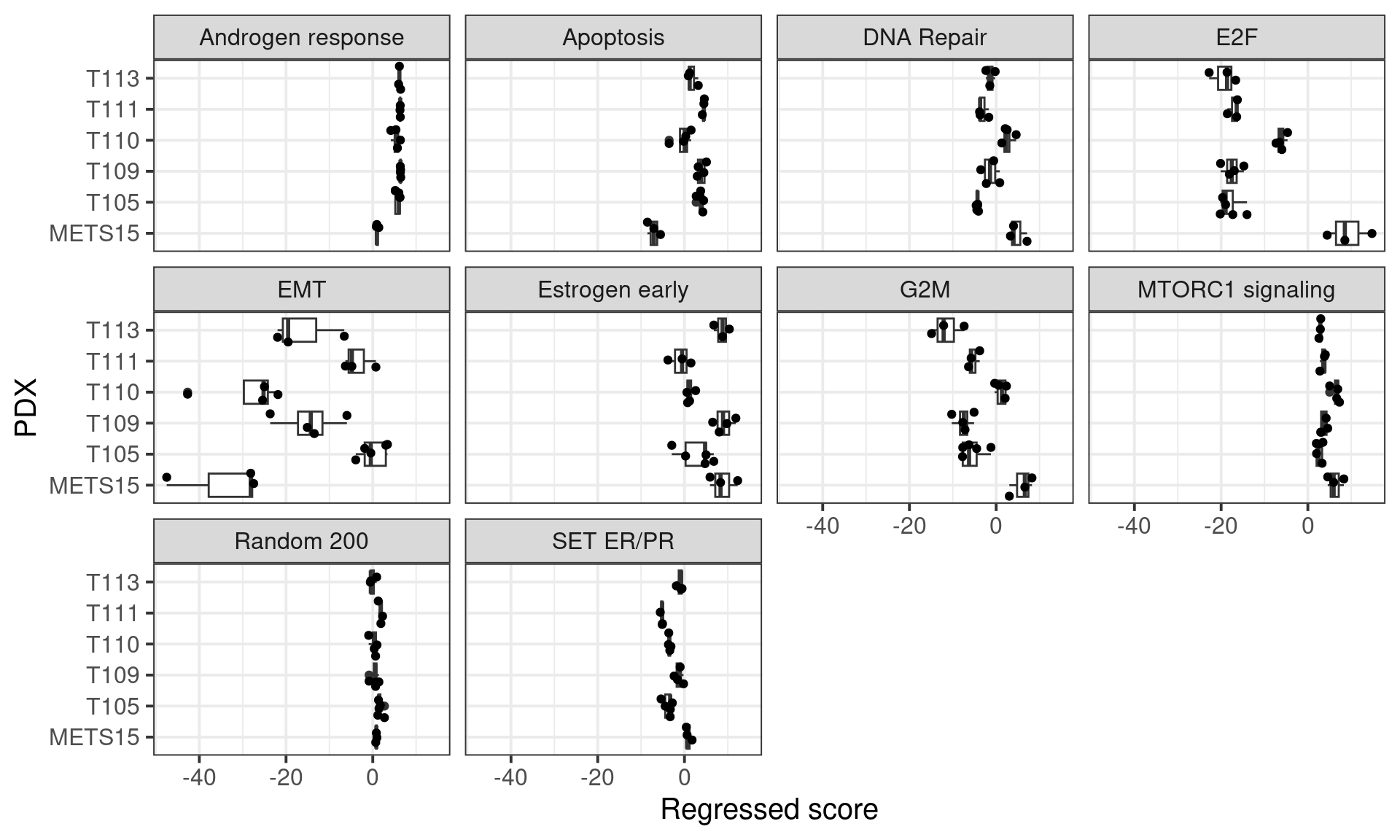
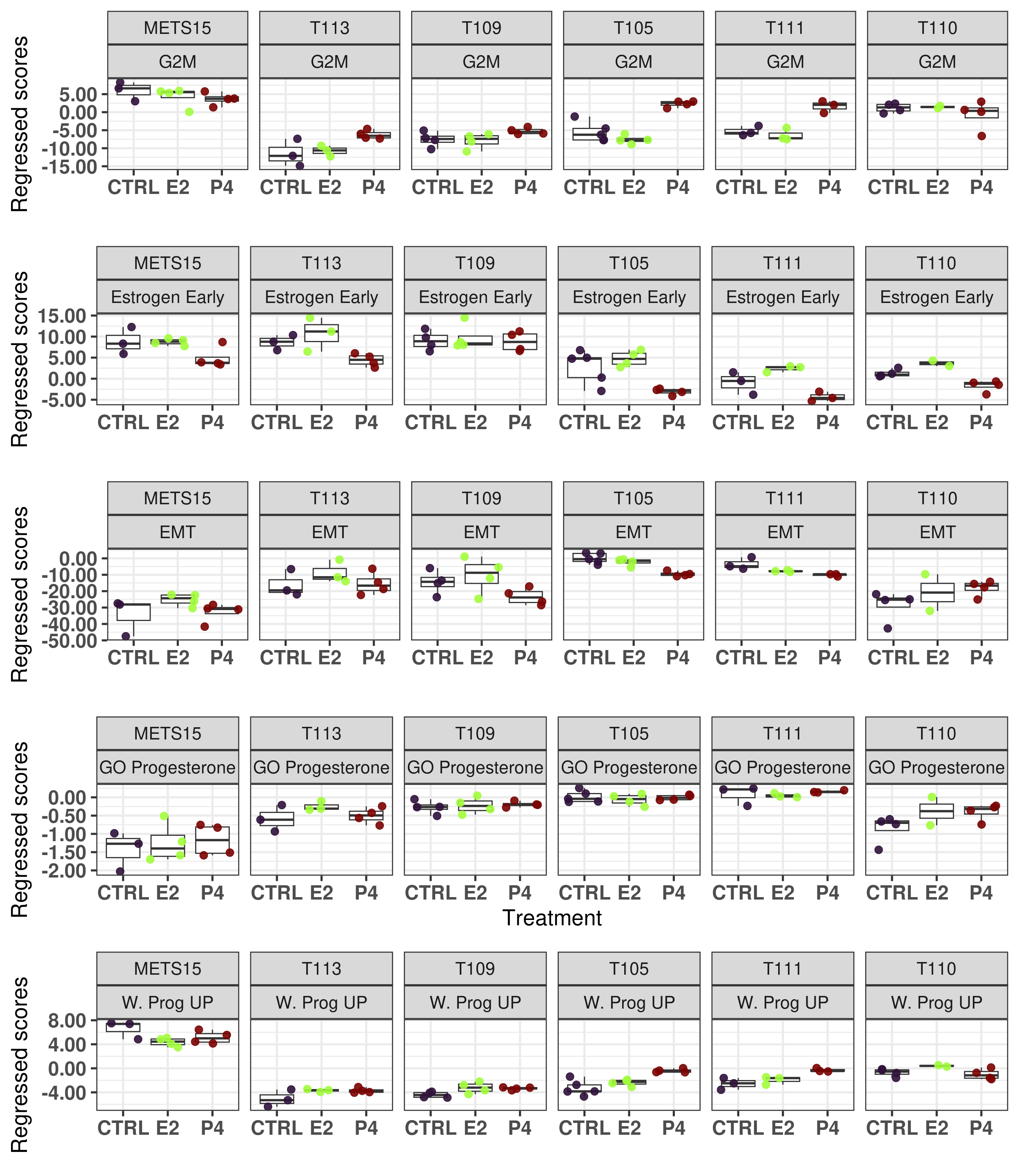
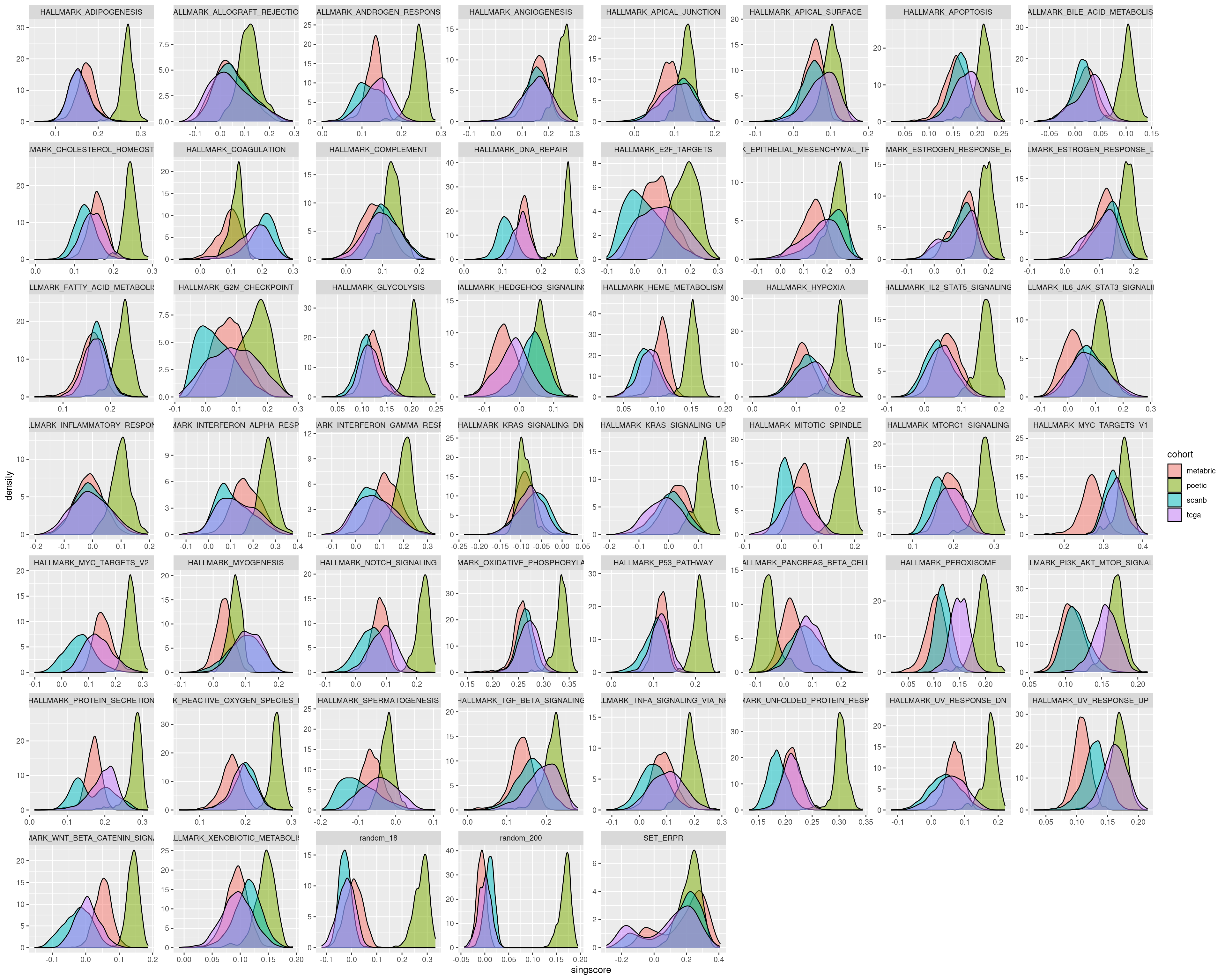
Figure 6.14: Scores obtained from the regressed data of the PDXs.
The random 200 is just a gene set with 200 random genes that works as a control and serves as a comparison to the other pathways.
And below we show the distribution of some of the scores calculated for all the other cohorts as a comparison.
We see that METS15 is the one with the highest proliferation and lowest EMT, it is a PDX that comes from a pleural efusion. Also it is the PDX with the lowest apoptosis and highest DNA repair, probably due to a higher replication rate. Moreover, all these PDXs they have a estrogen response early scores higher than 0 in average, which is about the average of the scores in the ER+ BC samples.
Now we check what happens with some of the PDXs when they are treated with P4, to compare with Figure 3.23.
Figure 6.15: Comparison of position in the molecular landscape between CTRL, E2 and P4 treated samples with the regressed data
The results are very similar to what was seen previously using the GSVA. What is interesting here is that we have an absolute scale, so we can compare the scores.
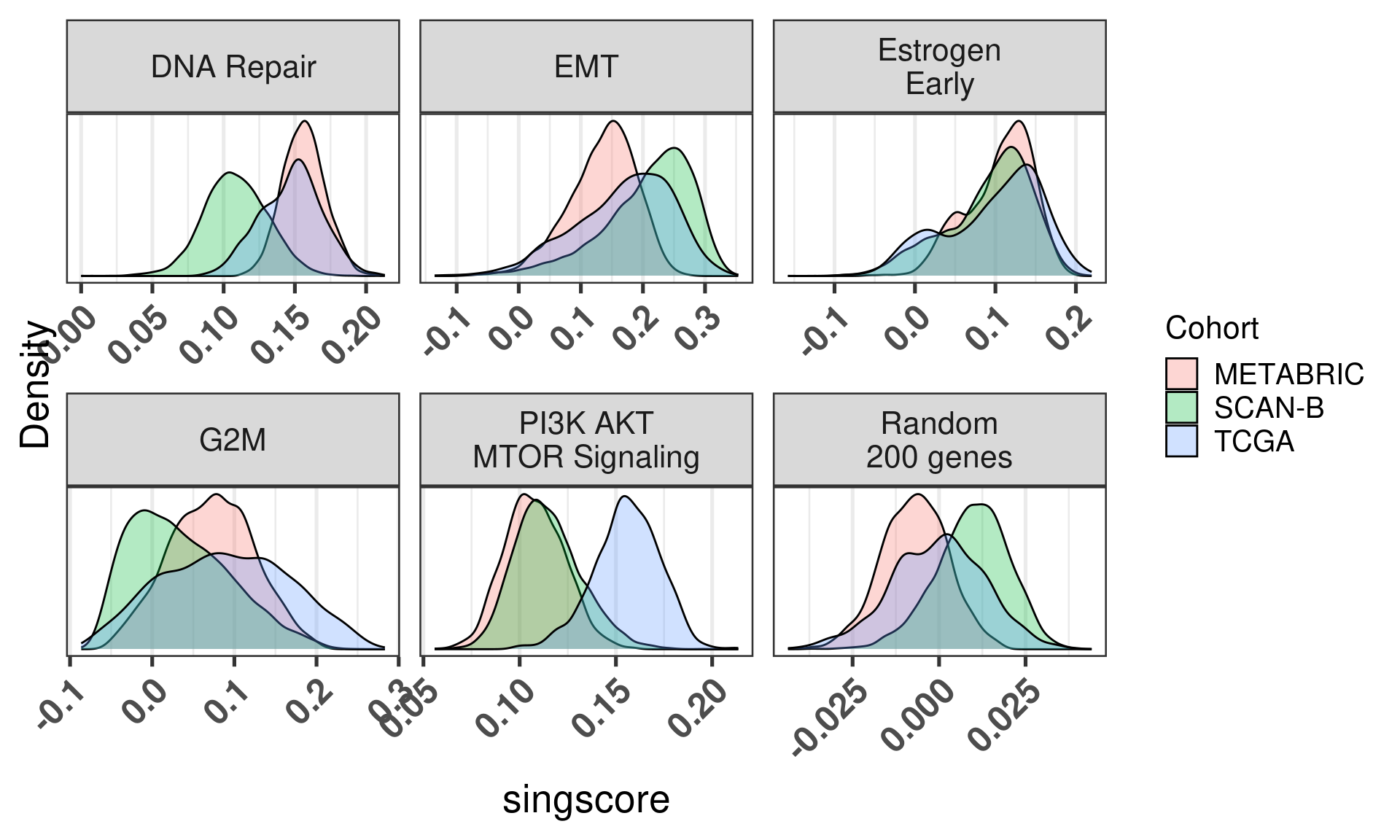
6.5 singscore
We can try to use singscore instead, it is a sample dependent measure so it does not estimate the distribution of the gene expression levels before calculating the enrichment score.
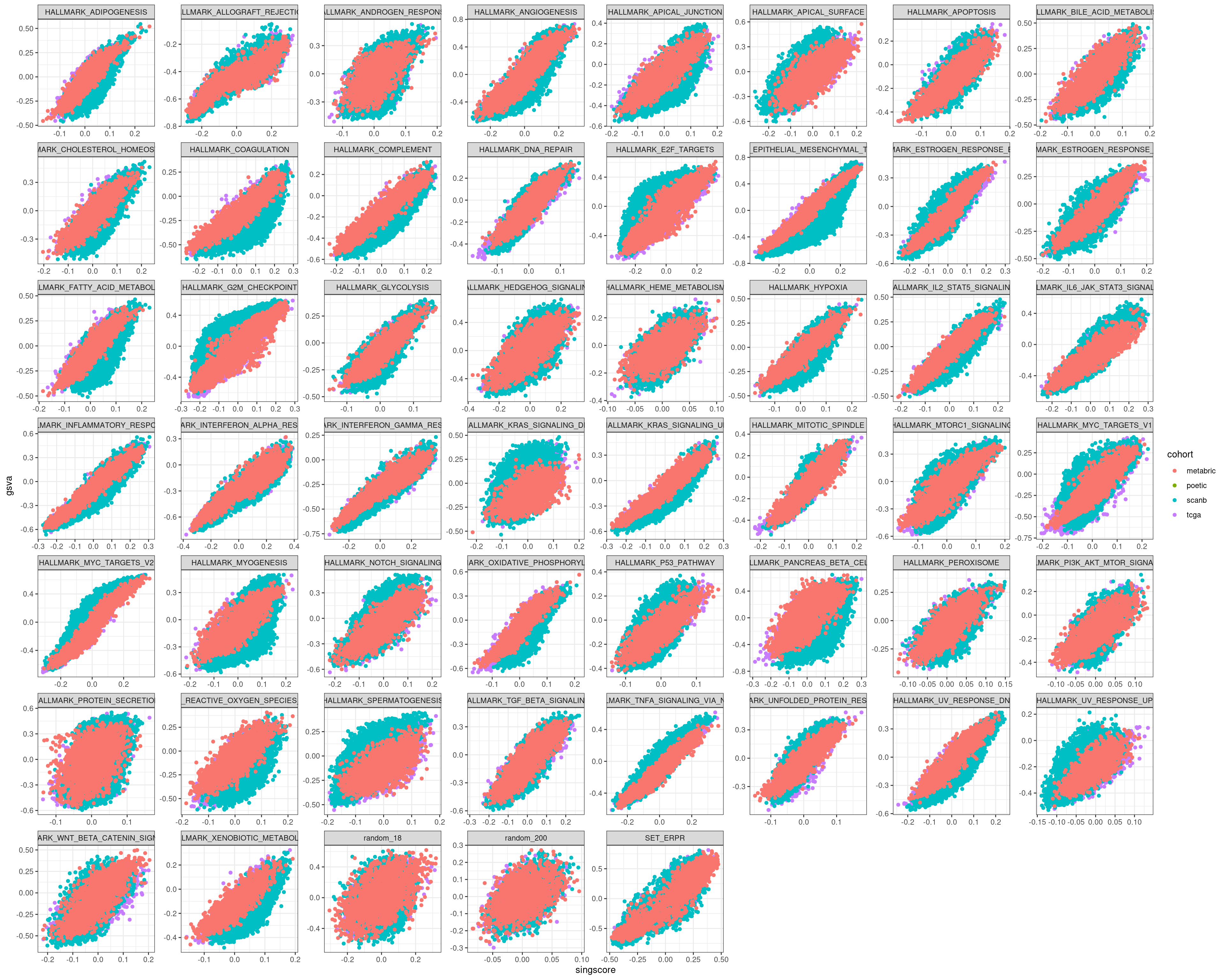
We start by comparing with the GSVA scores.
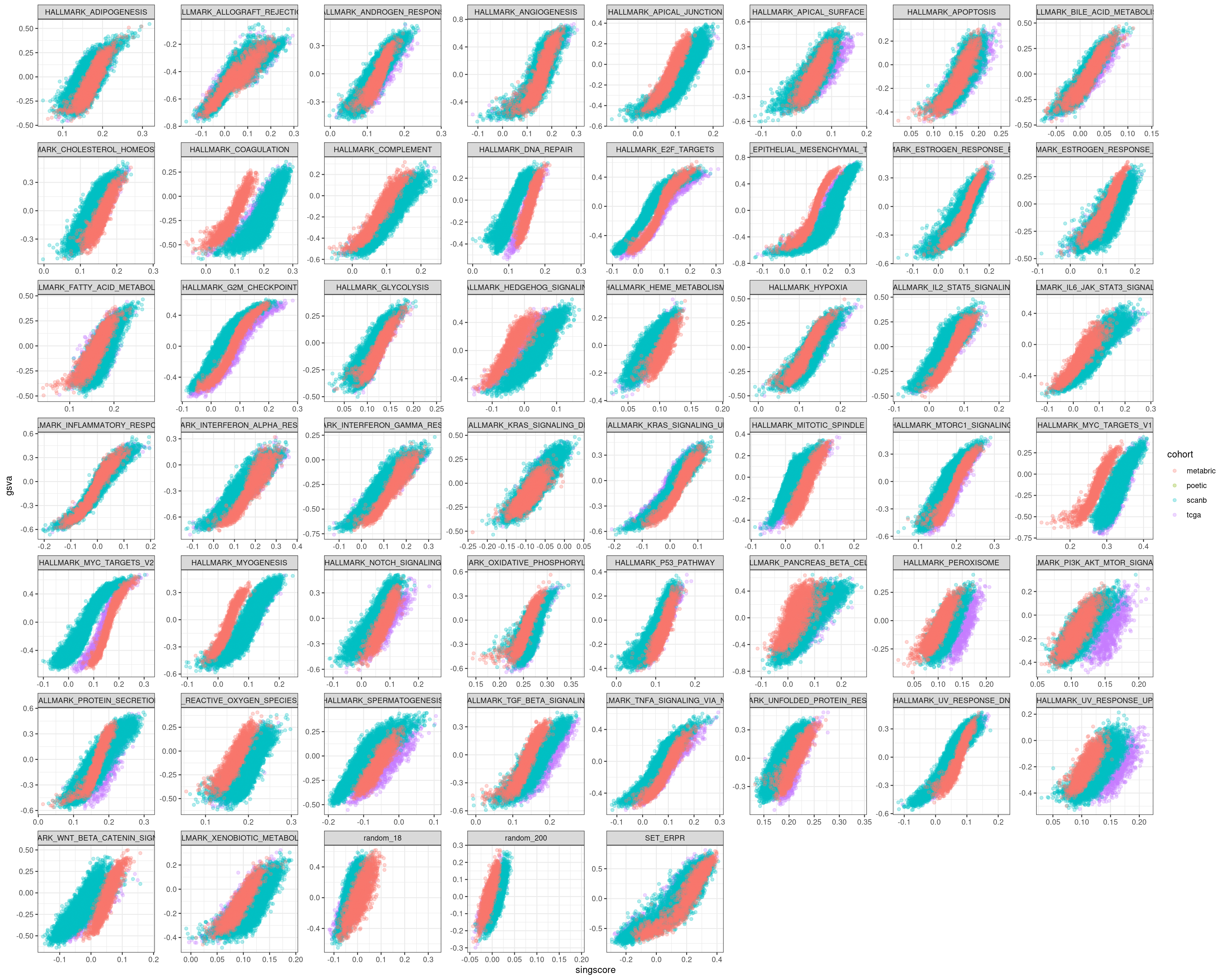
Figure 6.16
We see that in all cases there is a correlation, but the interpretation changes. In some of the pathways there is difference in the singscores based on the cohort, this is not seen on GSVA.
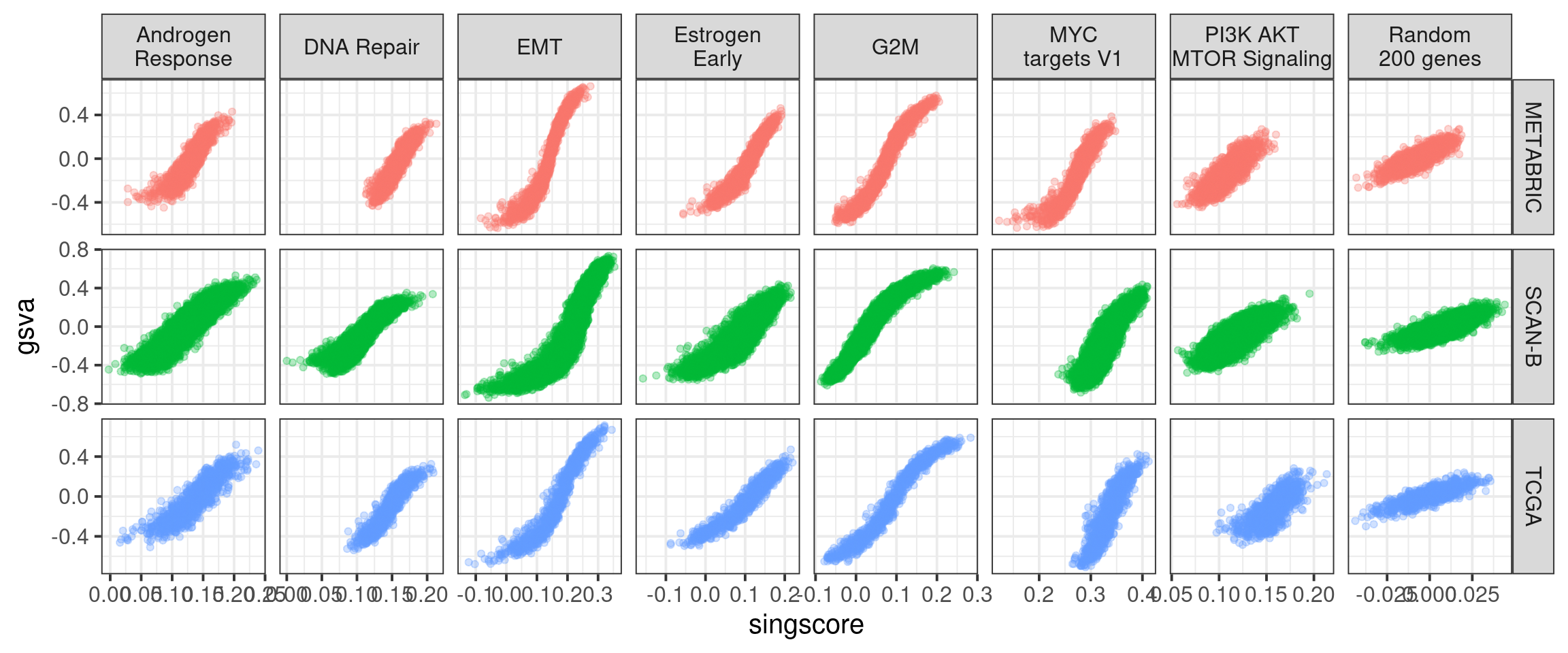
Figure 6.17
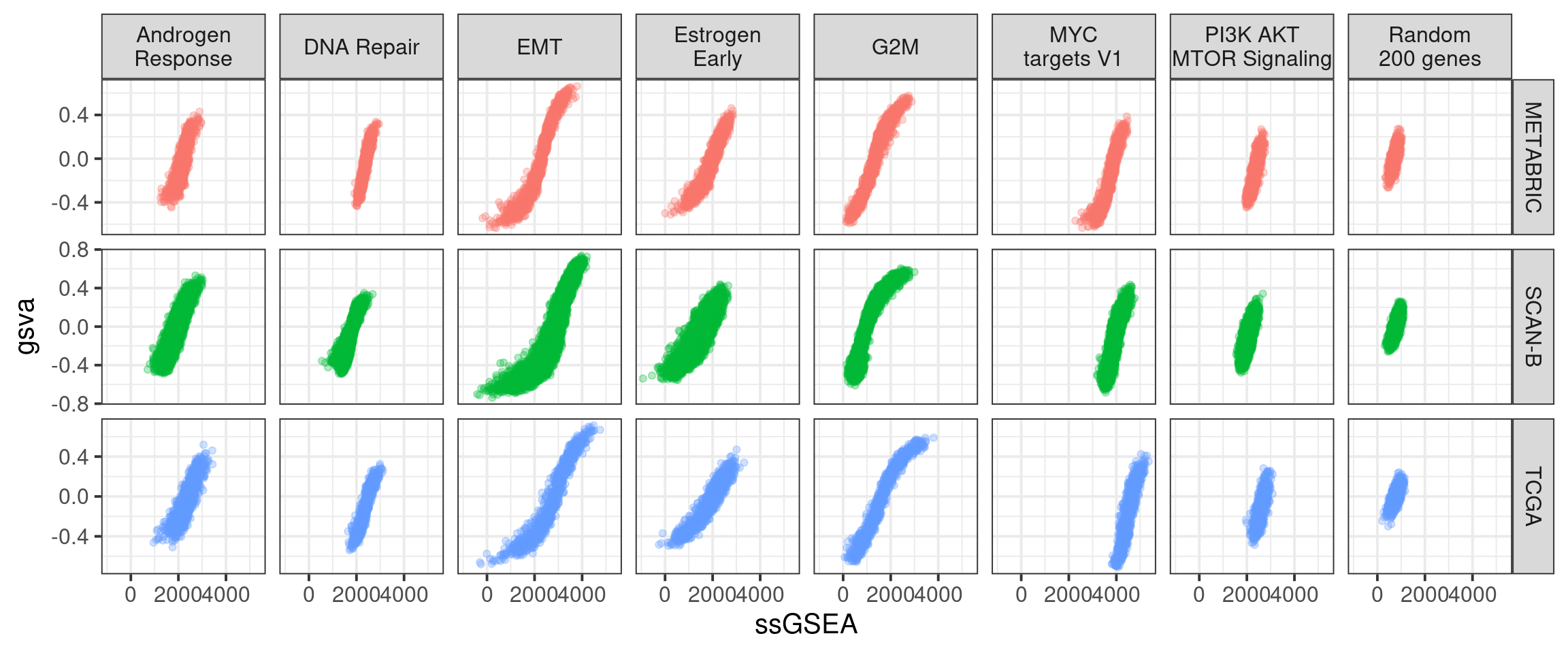
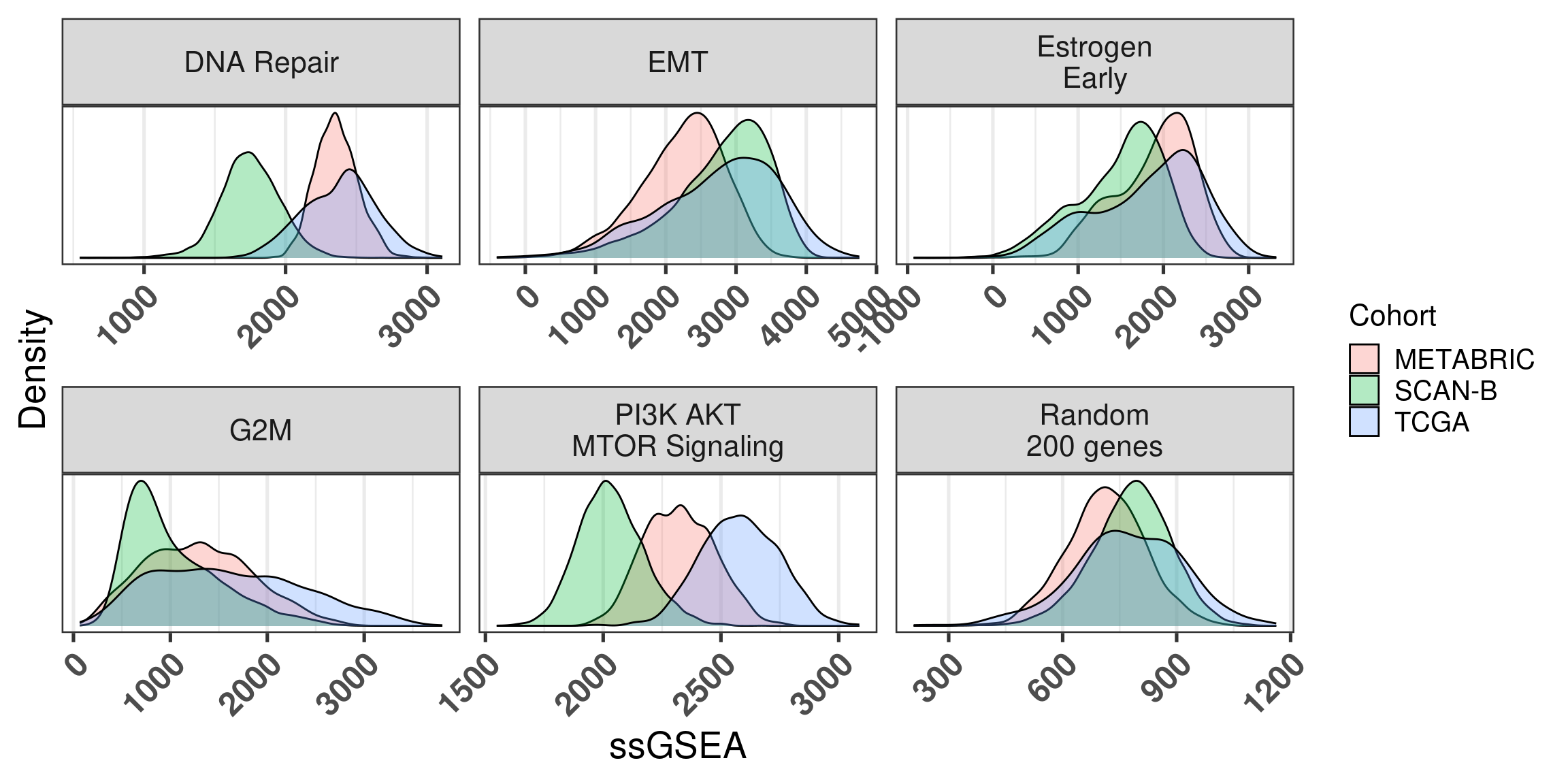
The next figure shows the same comparison but instead of using singscore, we used ssGSEA.
[1] "Calculating ranks..."
[1] "Calculating absolute values from ranks..."
[1] "Calculating ranks..."
[1] "Calculating absolute values from ranks..."
[1] "Calculating ranks..."
[1] "Calculating absolute values from ranks..."
[1] "Calculating ranks..."
[1] "Calculating absolute values from ranks..."
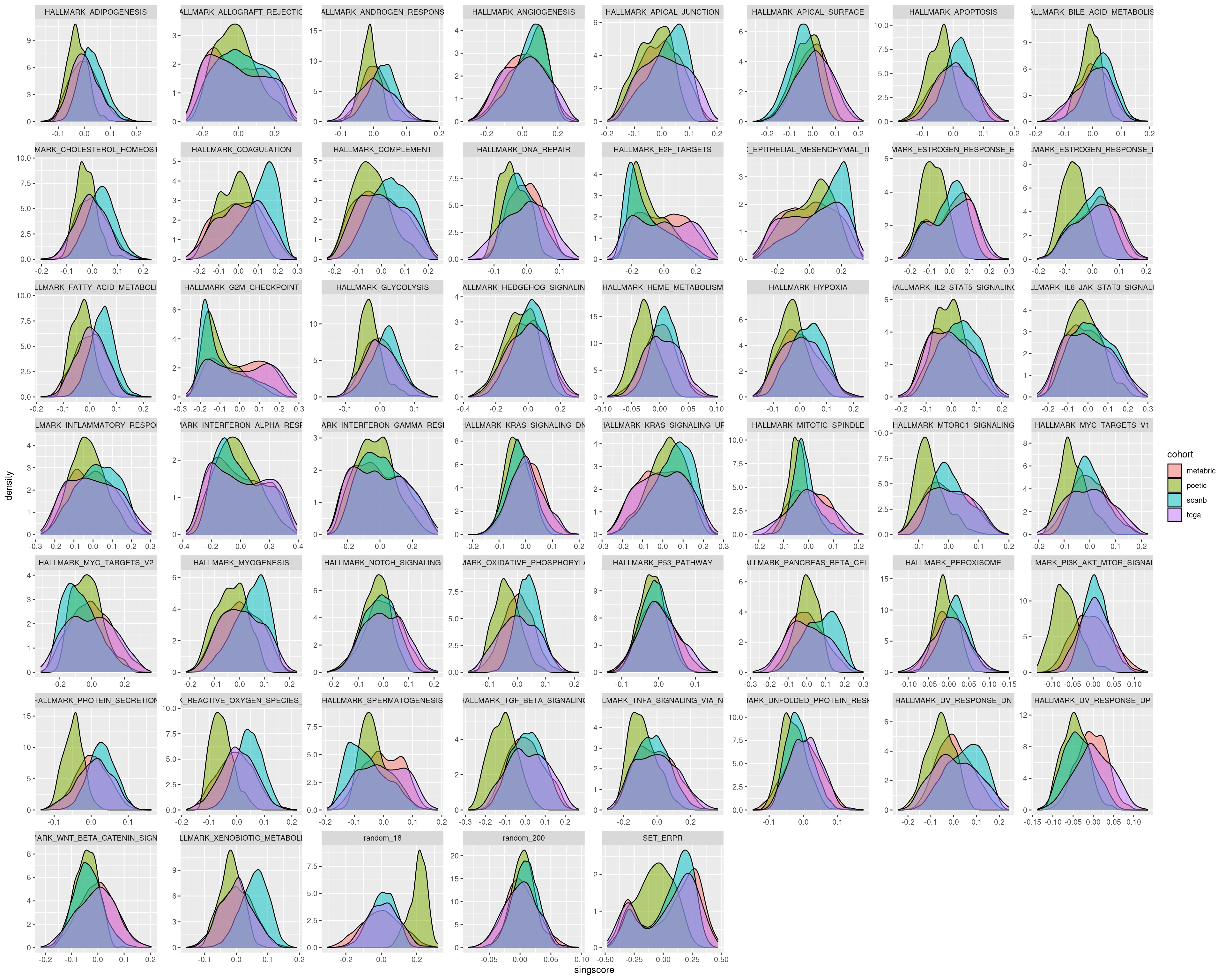
The picture is similar as before, but now we actually look at the distributions across the 3 big cohorts. We used ssGSEA without the normalization, as that would be necessary in the case of an individual sample.
Figure 6.18
We see that overall there is a discrepancy, sometimes big, depending on the pathway, including the random genes pathway. Next we show the same distribution for singscore. Similarly there is a big discrepancy in several cases.
Figure 6.19
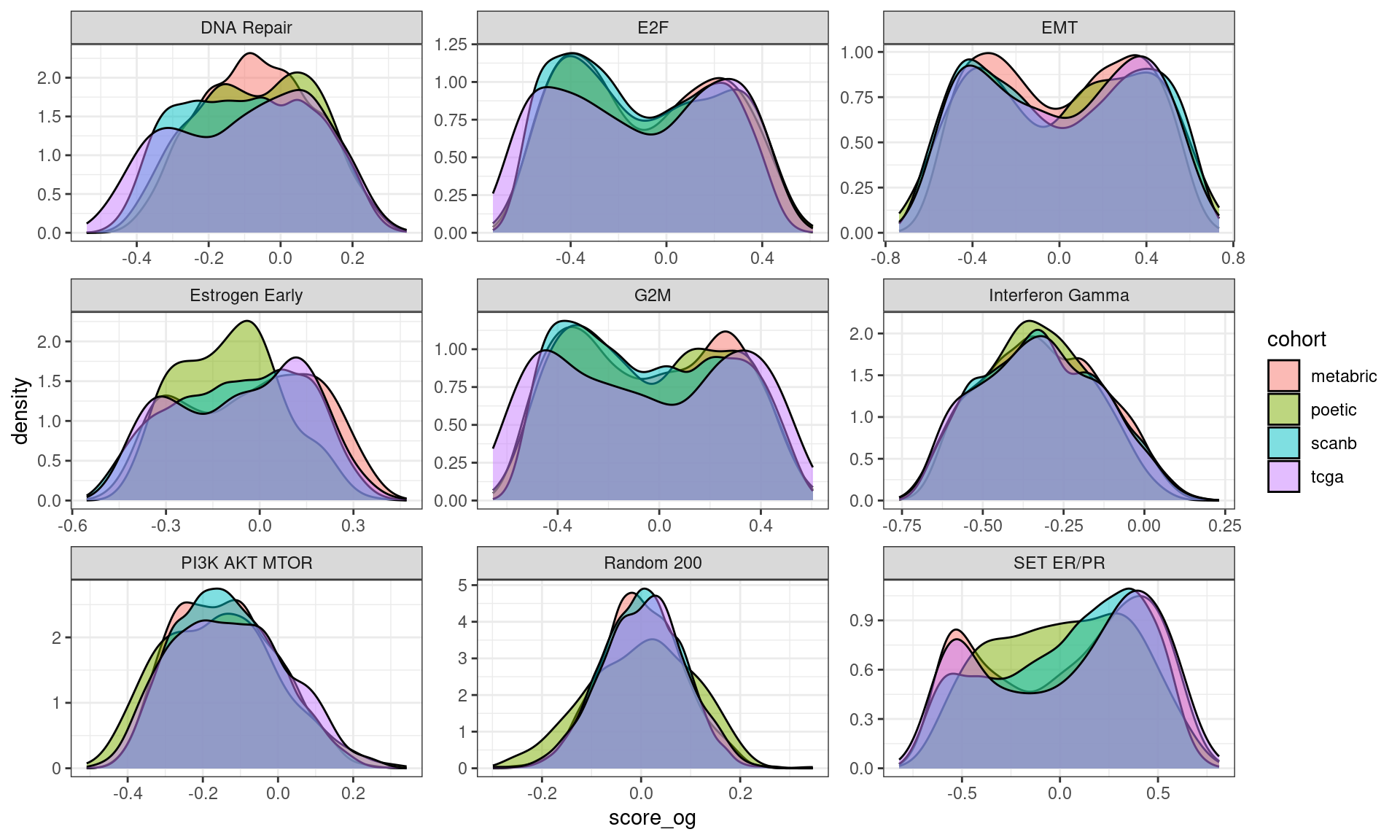
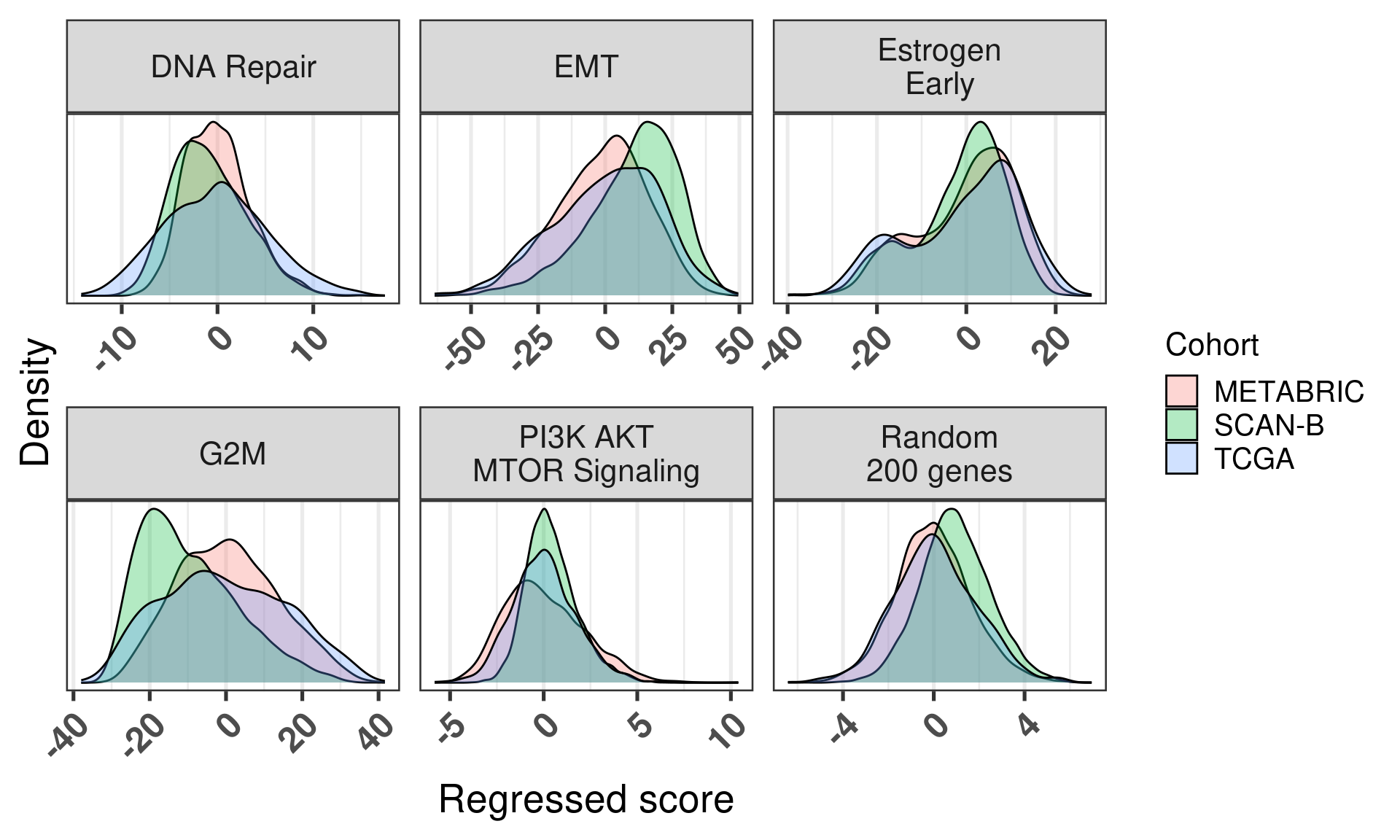
But now, Figure 6.20 shows that when we calculate the scores with the regressed data using our methodology the distributions are matched and adjusted, with the expection of G2M, which seems to be something more fundamental instead of batch effect. Note that all the distributions are overlapping significantly.
Figure 6.20
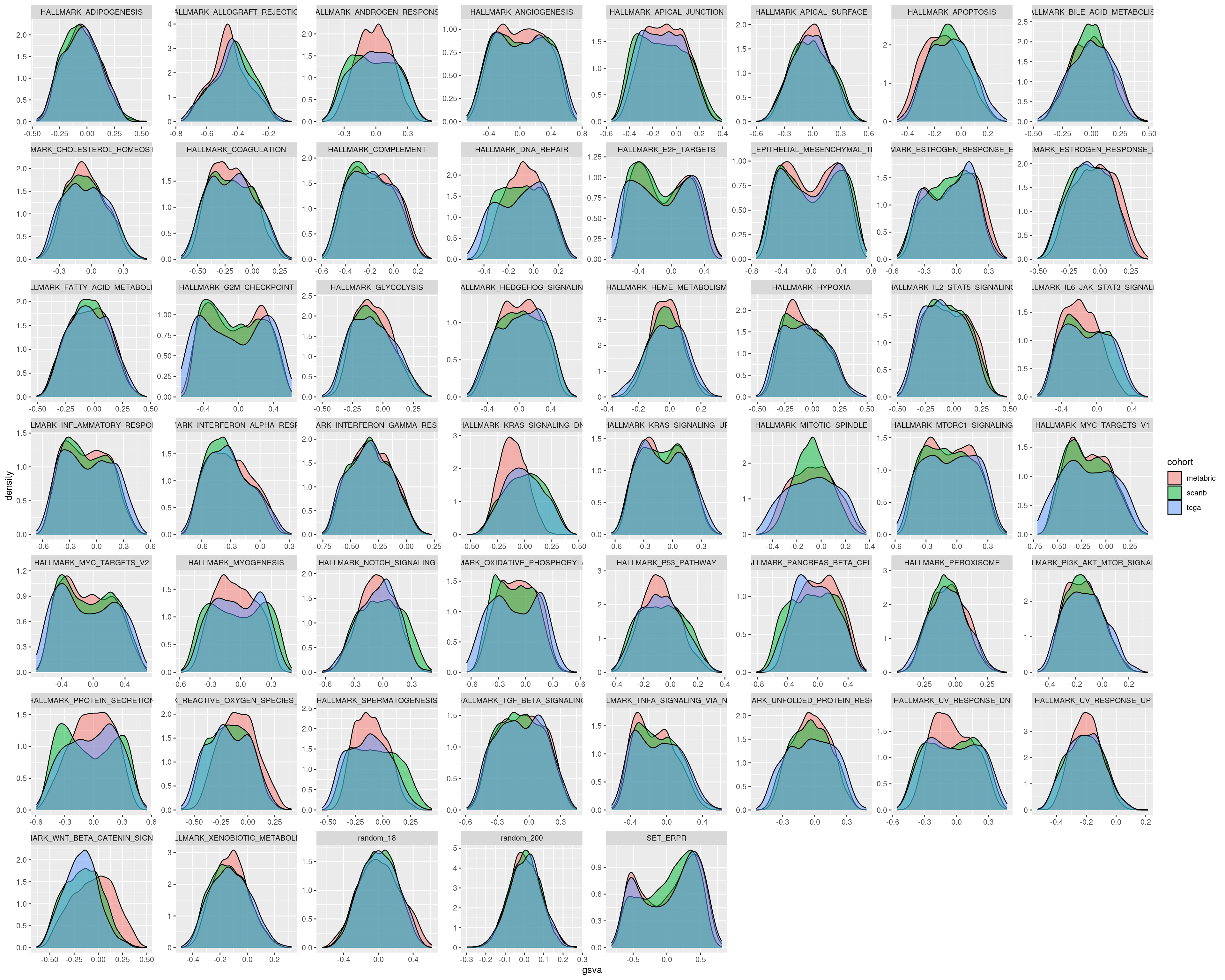
The next two figures are the distributions of the singscore and GSVA filled by cohort.
For several pathways in the singscore the distributions are similar, but that is not always the case.
On the other hand GSVA gives very similar distributions for all the different cohorts. Therefore we actually need to use GSVA. It is important in the end to calculate scores based on the cohort.
We now move on and try the same analysis on the regressed data.
We start by comparing with the GSVA scores.
We see that in all cases there is a correlation, but the interpretation changes. In some of the pathways there is difference in the singscores based on the cohort, this is not seen on GSVA.
The next two figures are the distributions of the singscore and GSVA filled by cohort.
In the end the best way of scoring seems to be using GSVA on the unregressed data though it depends on the pathways. For example the hallmark estrogen response early and set ER/PR pathways seem to have been regressed quite well, so we can actually compare the results using the scores. On the other hand we can’t use the pathways G2M checkpoint, E2F targets and EMT. For the PI3K signaling score it seems it is comparable to SCANB only.
Source Code
# Expanding embedding and removing batch effects We have used some numbers of genes for doing the embedding. Here we try to perform the embedding with all the genes (~10000 genes) and thenwe try to regress out the components. ```{r setup}renv::restore()library(tidyverse)library(ggplot2)library(PCAtools)library(singscore)library(SummarizedExperiment)library(survival)library(genefu)library(caret)source("../R/utils.R")source("../R/first_run.R")# the following script load all data necessary to run the chunks.# the data is generated from this quarto document itself, therefore# if you are running this documents the first time and don't have the# files, comment the following lines. Moreover, if this is your first# time running the document, you should run all chunks, to generate # all the necessary files, if you don't have them. Once all files # are saved and available in the respective folder, the following# lines can be executed. if (first_run){ load_at_setup <- FALSE} else { load_at_setup <- TRUE}name_document <- "expanding_ember"sapply( paste0("../../results/", c("plots", "rds_files", "tables"), "/", name_document), dir.create, showWarnings = FALSE, recursive = TRUE)source("../R/load_rds_files.R")# by setting the dev to png and pdf, this saves the figures in a specific# folder in both formats. moreover, since png is coming first, it shows# this figure when rendering the html. What is nice about this is that it# inherits the properties from the chunk to save the figure, so no need# to use ggplot2::ggsave to save the plots. this also works knitr::opts_chunk$set(dev = c('png', 'pdf'))options(bitmapType = 'cairo')p4_pathways <- msigdbr::msigdbr() %>% dplyr::filter(gs_name %in% c( "WILCOX_RESPONSE_TO_PROGESTERONE_UP", "GOBP_RESPONSE_TO_PROGESTERONE", "BIOCARTA_HER2_PATHWAY", "KEGG_ERBB_SIGNALING_PATHWAY" ))gene_sets_prog <- dplyr::bind_rows( gene_sets, p4_pathways)gene_sets_ <- sapply( gene_sets_prog$gs_name %>% unique, function(x, gene_sets) gene_sets %>% dplyr::filter(gs_name == x) %>% dplyr::pull(gene_symbol), gene_sets = gene_sets_prog, USE.NAMES = TRUE, simplify = FALSE)datasets$poetic$sample_name <- colnames(datasets$poetic)```## Embedding with more than 1000 genes```{r, eval = first_run}# we perform now the normalization for all genescommon_genes <- Reduce(intersect, lapply(datasets, rownames))stable_genes <- intersect(stable_genes, common_genes)datasets_normalized <- mapply( get_final_ranking_values, sum_exp = datasets, assay_to_use = c(which_exp, list(poetic = "normalized_intensity")), MoreArgs = list( stable_genes = stable_genes, most_variable_genes = common_genes ), USE.NAMES = TRUE, SIMPLIFY = FALSE)merged_col_data <- lapply(datasets_normalized, colData) %>% lapply(., data.frame) %>% dplyr::bind_rows(.id = "cohort")set.seed(1329)samples_for_training <- merged_col_data %>% dplyr::filter(cohort %in% which_cohorts_training) %>% dplyr::pull(sample_name) %>% sample(., size = 1000) # and now we can perform the molecular embeddingtraining_set <- lapply( datasets_normalized[which_cohorts_training], function(sum_exp, i, genes_for_pca) assay(sum_exp[genes_for_pca, ], i = i) %>% data.frame(check.names = FALSE), i = "avg_ranking", genes_for_pca = common_genes) %>% dplyr::bind_cols() %>% .[, samples_for_training]pca_fit_all_genes <- PCAtools::pca( training_set, metadata = dplyr::bind_rows( lapply( datasets_normalized[which_cohorts_training], function(df){ colData(df) %>% data.frame %>% dplyr::filter(sample_name %in% colnames(training_set)) } ), .id = "cohort" ) %>% .[colnames(training_set), ], center = FALSE, scale = FALSE)saveRDS( pca_fit_all_genes, "../../results/rds_files/expanding_ember/pca_fit_all_genes.rds")saveRDS( datasets_normalized, "../../results/rds_files/expanding_ember/datasets_normalized_all_genes.rds")saveRDS( merged_col_data, "../../results/rds_files/expanding_ember/merged_col_data_trying.rds")```And now we can visualize the results.```{r, fig.width=14, fig.height=16}#| label: fig-pca-embeddings-1#| fig-cap: PCA projections colored by different factors and organized#| by different components. (A) Plot of the first two components colored#| by cohort. (B) Plot of the first two components colored by ER status.#| (C) Plot of the second and third components colored by cohort. #| (D) Plot of the second and third components colored by ER status.#| (E) Plot of the second and third components colored by PAM50.#| (F) Plot of the second and third components colored by INTCLUST, only#| METABRIC has an assigned value for this variable, NAs are TCGA samples.plots_pca_fit <- list()point_size <- 2plots_pca_fit$pc1_pc2_cohort <- PCAtools::biplot( pca_fit_all_genes, colby = "cohort", lab = NULL, legendPosition = "right", x = "PC1", y = "PC2", title = "First two components colored by cohort", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc1_pc2_er_status <- PCAtools::biplot( pca_fit_all_genes, colby = "er_status", lab = NULL, legendPosition = "right", x = "PC1", y = "PC2", title = "First two components colored by ER status", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_cohort <- PCAtools::biplot( pca_fit_all_genes, colby = "cohort", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by cohort", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_er_status <- PCAtools::biplot( pca_fit_all_genes, colby = "er_status", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by ER status", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_pam50 <- PCAtools::biplot( pca_fit_all_genes, colby = "pam50", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by PAM50", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_pam50 <- plots_pca_fit$pc2_pc3_pam50 + ggplot2::scale_color_manual( values = get_colors_pam50(pca_fit_all_genes$metadata) )plots_pca_fit$pc2_pc3_intclust <- PCAtools::biplot( pca_fit_all_genes, colby = "INTCLUST", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by INTCLUST", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc3_pc4_pam50 <- PCAtools::biplot( pca_fit_all_genes, colby = "pam50", lab = NULL, legendPosition = "right", x = "PC3", y = "PC4", title = "Third and fourth components colored by PAM50", subtitle = "Only 1000 training samples", pointSize = point_size) plots_pca_fit$pc3_pc4_pam50 <- plots_pca_fit$pc3_pc4_pam50 + ggplot2::scale_color_manual( values = get_colors_pam50(pca_fit_all_genes$metadata) )plots_pca_fit$pc3_pc4_cohort <- PCAtools::biplot( pca_fit_all_genes, colby = "cohort", lab = NULL, legendPosition = "right", x = "PC3", y = "PC4", title = "Third and fourth components colored by cohort", subtitle = "Only 1000 training samples", pointSize = point_size)cowplot::plot_grid(plotlist = plots_pca_fit, ncol = 2, labels = "AUTO")``````{r, eval = first_run}datasets_pca_coordinates <- lapply( datasets_normalized, get_pca_coordinates, pca_fit = pca_fit_all_genes, genes_for_pca = rownames(pca_fit_all_genes$loadings))df_pca_coordinates <- datasets_pca_coordinates %>% do.call(rbind, .) %>% data.frame %>% tibble::rownames_to_column(var = "sample_name") %>% dplyr::inner_join( ., merged_col_data, by = "sample_name" )saveRDS( df_pca_coordinates, "../../results/rds_files/expanding_ember/df_pca_coordinates_all_genes.rds")``````{r}plot_pca_coordinates( df_pca_coordinates %>% dplyr::slice(1:n()),color ="cohort",x ="PC3",y ="PC4",size =1,base_size =10,title =paste0("Embedding of all samples from TCGA,\n","METABRIC and SCANB" )) + ggplot2::scale_color_viridis_d() + ggplot2::theme_bw(base_size =15) +change_plot_aes_point() +change_guides_point()``````{r, eval = first_run}remove_metabric <- df_pca_coordinates %>% dplyr::filter(PC4 > 10 & cohort == "metabric") %>% dplyr::pull(sample_name)set.seed(1329)samples_for_training <- merged_col_data %>% dplyr::filter(cohort %in% which_cohorts_training) %>% dplyr::pull(sample_name) %>% sample(., size = 1000) %>% setdiff(., remove_metabric)# and now we can perform the molecular embeddingtraining_set <- lapply( datasets_normalized[which_cohorts_training], function(sum_exp, i, genes_for_pca) assay(sum_exp[genes_for_pca, ], i = i) %>% data.frame(check.names = FALSE), i = "avg_ranking", genes_for_pca = common_genes) %>% dplyr::bind_cols() %>% .[, samples_for_training]pca_fit_all_genes_wo_outliers <- PCAtools::pca( training_set, metadata = dplyr::bind_rows( lapply( datasets_normalized[which_cohorts_training], function(df){ colData(df) %>% data.frame %>% dplyr::filter(sample_name %in% colnames(training_set)) } ), .id = "cohort" ) %>% .[colnames(training_set), ], center = FALSE, scale = FALSE)saveRDS( pca_fit_all_genes_wo_outliers, "../../results/rds_files/expanding_ember/pca_fit_all_genes_wo_outliers.rds")```And now we can visualize the results.```{r, fig.width=14, fig.height=16}#| label: fig-pca-embeddings-2#| fig-cap: PCA projections colored by different factors and organized#| by different components. (A) Plot of the first two components colored#| by cohort. (B) Plot of the first two components colored by ER status.#| (C) Plot of the second and third components colored by cohort. #| (D) Plot of the second and third components colored by ER status.#| (E) Plot of the second and third components colored by PAM50.#| (F) Plot of the second and third components colored by INTCLUST, only#| METABRIC has an assigned value for this variable, NAs are TCGA samples.plots_pca_fit <- list()point_size <- 2plots_pca_fit$pc1_pc2_cohort <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "cohort", lab = NULL, legendPosition = "right", x = "PC1", y = "PC2", title = "First two components colored by cohort", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc1_pc2_er_status <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "er_status", lab = NULL, legendPosition = "right", x = "PC1", y = "PC2", title = "First two components colored by ER status", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_cohort <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "cohort", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by cohort", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_er_status <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "er_status", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by ER status", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_pam50 <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "pam50", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by PAM50", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc2_pc3_pam50 <- plots_pca_fit$pc2_pc3_pam50 + ggplot2::scale_color_manual( values = get_colors_pam50(pca_fit_all_genes_wo_outliers$metadata) )plots_pca_fit$pc2_pc3_intclust <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "INTCLUST", lab = NULL, legendPosition = "right", x = "PC2", y = "PC3", title = "Second and third components colored by INTCLUST", subtitle = "Only 1000 training samples", pointSize = point_size)plots_pca_fit$pc3_pc4_pam50 <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "pam50", lab = NULL, legendPosition = "right", x = "PC3", y = "PC4", title = "Third and fourth components colored by PAM50", subtitle = "Only 1000 training samples", pointSize = point_size) plots_pca_fit$pc3_pc4_pam50 <- plots_pca_fit$pc3_pc4_pam50 + ggplot2::scale_color_manual( values = get_colors_pam50(pca_fit_all_genes_wo_outliers$metadata) )plots_pca_fit$pc3_pc4_cohort <- PCAtools::biplot( pca_fit_all_genes_wo_outliers, colby = "cohort", lab = NULL, legendPosition = "right", x = "PC3", y = "PC4", title = "Third and fourth components colored by cohort", subtitle = "Only 1000 training samples", pointSize = point_size)cowplot::plot_grid(plotlist = plots_pca_fit, ncol = 2, labels = "AUTO")``````{r, eval = first_run}datasets_pca_coordinates <- lapply( datasets_normalized, get_pca_coordinates, pca_fit = pca_fit_all_genes_wo_outliers, genes_for_pca = rownames(pca_fit_all_genes_wo_outliers$loadings))df_pca_coordinates_wo_outliers <- datasets_pca_coordinates %>% do.call(rbind, .) %>% data.frame %>% tibble::rownames_to_column(var = "sample_name") %>% dplyr::inner_join( ., merged_col_data, by = "sample_name" )saveRDS( df_pca_coordinates_wo_outliers, "../../results/rds_files/expanding_ember/df_pca_coordinates_wo_outliers.rds")``````{r}plot_pca_coordinates( df_pca_coordinates_wo_outliers %>% dplyr::slice(1:n()),color ="cohort",x ="PC3",y ="PC4",size =1,base_size =10,title =paste0("Embedding of all samples from TCGA,\n","METABRIC and SCANB" )) + ggplot2::scale_color_viridis_d() + ggplot2::theme_bw(base_size =15) +change_plot_aes_point() +change_guides_point()``````{r}#| label: fig-pca-scanb-pc1#| fig-cap: PCA embedding colored by cohort. The components used are the#| first and second components.plot_pca_coordinates( df_pca_coordinates_wo_outliers,color ="cohort",x ="PC1",y ="PC2",size =1,base_size =10,title =paste0("Embedding of all samples from TCGA,\n","METABRIC and SCANB" )) + ggplot2::theme_bw(base_size =15) +change_plot_aes_point() +change_guides_point()```@fig-pca-scanb-er-pam50-all-genes shows that the SCANB samples are also well mixedregarding the clinical factors, including the $SET_{ER/PR}$ signature.```{r, fig.width=16, fig.height=12}#| label: fig-pca-scanb-er-pam50-all-genes#| fig-cap: PCA embedding of all samples from TCGA, SCANB and METABRIC.#| (A) Colored by cohort,#| (B) colored by ER status, (C) colored by PAM50 molecular subtype,#| (D) colored by the $SET_{ER/PR}$ signature and only SCANB samples.size <- 2base_size <- 20plots_with_scanb <- sapply( c("cohort", "er_status", "pam50", "SET_ERPR"), plot_pca_coordinates, df_pca = df_pca_coordinates_wo_outliers %>% dplyr::filter( pam50 %in% c("luma", "lumb", "basal", "her2", "normal") ) %>% dplyr::filter(!(cohort %in% c("poetic"))) %>% dplyr::slice(sample(1:n())), x = "PC3", y = "PC4", size = size, base_size = base_size, title = paste0( "Embedding of all samples from TCGA,\n", "METABRIC and SCANB" ), USE.NAMES = TRUE, simplify = FALSE)plots_with_scanb$cohort <- plots_with_scanb$cohort + change_plot_aes_point() + change_guides_point()plots_with_scanb$pam50 <- plots_with_scanb$pam50 + ggplot2::scale_color_manual( values = get_colors_pam50(plots_with_scanb$pam50$data) ) + ggplot2::labs(color = "Molecular\nsubtype") + change_plot_aes_point() + change_guides_point()plots_with_scanb$er_status <- plots_with_scanb$er_status + ggplot2::scale_color_viridis_d() + ggplot2::labs(color = "ER status") + change_plot_aes_point() + change_guides_point()plots_with_scanb$SET_ERPR <- df_pca_coordinates_wo_outliers %>% dplyr::filter(cohort %in% c("scanb")) %>% ggplot2::ggplot(aes_string(x = "PC3", y = "PC4", z = "SET_ERPR")) + ggplot2::stat_summary_hex(bins = 25) + ggplot2::scale_fill_viridis_c() + ggplot2::labs( title = "Embedding of SCANB only", fill = expression(SET[ER/PR]) ) + ggplot2::theme_bw(base_size = base_size) + change_plot_aes_point()cowplot::plot_grid( plotlist = plots_with_scanb, ncol = 2)``````{r, fig.width=12, fig.height=8}select_pcs <- paste0("PC", 1:30)pca_fit_all_genes_wo_outliers$loadings %>% data.frame %>% dplyr::select(dplyr::all_of(select_pcs)) %>% tidyr::pivot_longer( cols = dplyr::all_of(select_pcs), names_to = "component", values_to = "loadings" ) %>% ggplot2::ggplot( aes(x = abs(loadings)) ) + ggplot2::geom_histogram(bins = 30) + ggplot2::facet_wrap(~component) + ggplot2::labs( title = "Histogram of the loadings from the first four components" ) + ggplot2::theme_bw(base_size = 20) + change_plot_aes_point()```Let us also check the other components in the biplots.```{r, fig.width=16, fig.height=12}color_by <- "pam50"GGally::ggpairs( df_pca_coordinates_wo_outliers %>% dplyr::filter(sample_name %in% pca_fit_all_genes_wo_outliers$metadata$sample_name ) %>% dplyr::select(dplyr::all_of(c(paste0("PC", 1:10), color_by))), aes(color = !!sym(color_by), alpha = 0.5))```We see that the pam50 subtypes are being separated using the components 3, 4and also 8. In the component 8 there is some expression that is able to differentiate between HER2-like from all other samples.We now plot by cohort.```{r, fig.width=16, fig.height=12}color_by <- "cohort"GGally::ggpairs( df_pca_coordinates_wo_outliers %>% dplyr::filter(sample_name %in% pca_fit_all_genes_wo_outliers$metadata$sample_name ) %>% dplyr::select(dplyr::all_of(c(paste0("PC", 1:10), color_by))), aes(color = !!sym(color_by), alpha = 0.5))```In PC1, 2 and 5 there are some small differences in the differences of the distributions from the datasets. We will then remove these 3 componentsup to component 10 with exception of components 3, 4 and 5.## Removing the batch effectsWe now try to remove the batch effects by removing all the PCs that are notof interest, so we remove the first two components and the fifth as well. Wethen calculate the scores for each cohort separately and then compareto what was calculated before. We can then try to calculate the scoresusing samples coming from all cohorts.```{r, eval = first_run}data_together <- lapply( datasets_normalized, \(x, y) assay(x, y) %>% as.matrix, "avg_ranking") %>% Reduce(cbind, .)samples_for_training <- pca_fit_all_genes_wo_outliers$metadata$sample_namerownames(df_pca_coordinates_wo_outliers) <- df_pca_coordinates_wo_outliers$sample_namename_components <- colnames(pca_fit_all_genes_wo_outliers$loadings)# from previous analysis we decided that the component 5 still included# differences between the two datasets, so we decided to remove it as well # besides component 1 and 2remove_components <- paste0("PC", c(1, 2, 5))keep_components <- setdiff(name_components, remove_components)# the code below calculates the regressed dataframe for all samples from# scanb, tcga and metabricdf_pcs_regressed <- as.matrix( df_pca_coordinates_wo_outliers[colnames(data_together), keep_components]) %*% t(pca_fit_all_genes_wo_outliers$loadings[, keep_components]) %>% tpca_removed_pcs <- PCAtools::pca( mat = df_pcs_regressed[, samples_for_training], metadata = pca_fit_all_genes_wo_outliers$metadata)pca_all_samples_wo_pcs <- t(df_pcs_regressed %>% as.matrix) %*% (pca_removed_pcs$loadings %>% as.matrix)df_pca_wo_pcs <- pca_all_samples_wo_pcs %>% data.frame %>% tibble::rownames_to_column(var = "sample_name") %>% dplyr::inner_join( df_pca[, !grepl("PC", colnames(df_pca))], by = "sample_name" )saveRDS( df_pca_wo_pcs, "../../results/rds_files/expanding_ember/df_pca_wo_pcs.rds")saveRDS( pca_removed_pcs, "../../results/rds_files/expanding_ember/pca_removed_pcs.rds")saveRDS( df_pcs_regressed, "../../results/rds_files/expanding_ember/df_pcs_regressed.rds")``````{r}PCAtools::biplot( pca_removed_pcs,lab =NULL,colby ="cohort",legendPosition ="right")``````{r}PCAtools::biplot( pca_removed_pcs,lab =NULL,colby ="pam50",legendPosition ="right")```In general it looks good, the luminal B population is a bit compressed towards the luminal A population though.```{r, fig.width = 6, fig.height = 4}size_dots <- 1alpha_val <- 0.8base_size <- 10size_legend <- 5ggplot2::ggplot(df_pca_wo_pcs, aes(x = PC1, y = PC2, color = cohort)) + ggplot2::geom_point(size = size_dots, alpha = alpha_val) + ggplot2::scale_alpha(guide = 'none') + ggplot2::labs( color = "PAM50" ) + ggplot2::theme_bw(base_size = base_size)```There is a very good merging of the datasets. We see mostlygreen points because they are the majority. ```{r, fig.width=10, fig.height=8}pcs_loadings_plot <- paste0("PC", 1:10)pca_removed_pcs$loadings %>% data.frame %>% dplyr::select(dplyr::all_of(pcs_loadings_plot)) %>% tidyr::pivot_longer( cols = dplyr::all_of(pcs_loadings_plot), names_to = "component", values_to = "loadings" ) %>% dplyr::mutate(component = factor(component, levels = pcs_loadings_plot)) %>% ggplot2::ggplot( aes(x = abs(loadings)) ) + ggplot2::geom_histogram(bins = 30) + ggplot2::facet_wrap(~component) + ggplot2::labs( title = "Histogram of the loadings from the first four components" ) + ggplot2::theme_bw(base_size = 20)```Now we see that the first loadings has a tail in a similar fashio as theother loadings. We now try to calculate the scores of the samples using these new embeddingsonly from TCGA samples as we will compare the results later on. ```{r, eval = first_run}gsva_scores_embeddings_tcga <- GSVA::gsva( df_pcs_regressed[, merged_col_data %>% dplyr::filter(cohort == "tcga") %>% dplyr::pull(sample_name)], gene_sets_, parallel.sz = 10, verbose = FALSE)saveRDS( gsva_scores_embeddings_tcga, "../../results/rds_files/expanding_ember/gsva_scores_embeddings_tcga.rds")```And we can now check and compare the scores.```{r, fig.width=10, fig.height=5}pathways_of_interest <- c( "HALLMARK_ESTROGEN_RESPONSE_EARLY", "HALLMARK_G2M_CHECKPOINT", "SET_ERPR")sapply( pathways_of_interest, get_merged_df_scores, df1 = gsva_scores_embeddings_tcga, df2 = df_pca, USE.NAMES = TRUE, simplify = FALSE) %>% dplyr::bind_rows(.id = "pathway") %>% ggplot2::ggplot(aes(x = df1, y = df2)) + ggplot2::geom_point() + ggplot2::facet_wrap(~pathway) + ggplot2::geom_abline(slope = 1, intercept = 0, color = "red") + ggplot2::labs( x = "GSVA scores from regressed data", y = "GSVA scores from unregressed data", title = "TCGA scores" ) + ggplot2::theme_bw()```We see that for the three pathways the correlation is positive andstrong. The difference is that it is a bit noisy, so the correlationis not perfect. What is interesting to see is that at the extremesthe scores have less variation usually. We now calculate the scores from SCANB and compare the results. Rememberthat SCANB was not used for the PCA training.```{r, eval = first_run}gsva_scores_embeddings_scanb <- GSVA::gsva( df_pcs_regressed[, merged_col_data %>% dplyr::filter(cohort == "scanb") %>% dplyr::pull(sample_name)], gene_sets_, parallel.sz = 10, verbose = FALSE)saveRDS( gsva_scores_embeddings_scanb, "../../results/rds_files/expanding_ember/gsva_scores_embeddings_scanb.rds")```And we can now check and compare the scores.```{r, fig.width=10, fig.height=5}sapply( pathways_of_interest, get_merged_df_scores, df1 = gsva_scores_embeddings_scanb, df2 = df_pca, USE.NAMES = TRUE, simplify = FALSE) %>% dplyr::bind_rows(.id = "pathway") %>% ggplot2::ggplot(aes(x = df1, y = df2)) + ggplot2::geom_point() + ggplot2::facet_wrap(~pathway) + ggplot2::geom_abline(slope = 1, intercept = 0, color = "red") + ggplot2::labs( x = "GSVA scores from regressed data", y = "GSVA scores from unregressed data", title = "TCGA scores" ) + ggplot2::theme_bw()```The same phenomenon happened. Samples in the endges have lower variability,but samples in the middle are the ones that have high variability.For example there are several samples from the regressed datawith SET_ERPR score close to 0.25 and negative scores.What happens now if we use another dataset and then use only one sample to calculate the score. Let us include SCANB samples in the pipeline. For this we select 50 scanb samples and 100 random samples from tcga and metabric.We then combine all these samples together and calculate the GSVA scores.```{r, eval = first_run}scanb_samples <- df_pca %>% dplyr::filter(cohort == "scanb") %>% dplyr::slice_sample(n = 50) %>% dplyr::pull(sample_name)gsva_scores_embeddings_scanb_within_tcga <- parallel::mclapply( scanb_samples, function(x){ GSVA::gsva( df_pcs_regressed[ , merged_col_data %>% dplyr::filter(cohort %in% c("tcga", "metabric")) %>% dplyr::slice_sample(n = 100) %>% dplyr::pull(sample_name) %>% c(., x) ], gene_sets_, verbose = FALSE ) }, mc.cores = 10)saveRDS( gsva_scores_embeddings_scanb_within_tcga, "../../results/rds_files/expanding_ember/gsva_scores_embeddings_scanb_within_tcga.rds" )```We now plot only the scores from the SCANB samples.```{r, fig.width=10, fig.height=5}lapply( gsva_scores_embeddings_scanb_within_tcga, function(x){ sapply( pathways_of_interest, get_merged_df_scores, df1 = x, df2 = df_pca %>% dplyr::filter(cohort == "scanb"), USE.NAMES = TRUE, simplify = FALSE ) %>% dplyr::bind_rows(.id = "pathway") }) %>% dplyr::bind_rows(.id = "sample_name") %>% ggplot2::ggplot(aes(x = df1, y = df2)) + ggplot2::geom_point() + ggplot2::facet_wrap(~pathway) + ggplot2::geom_abline(slope = 1, intercept = 0, color = "red") + ggplot2::labs( x = "GSVA scores from regressed data", y = "GSVA scores from unregressed data", title = "TCGA scores" ) + ggplot2::theme_bw()```So it seems there are still dataset related problems there when calculatingthe scores. The scores are positively correlated, but they are not quitethe same as only using the SCANB dataset. Moreover, for G2M checkpoint the scores are concentrated around -0.4 from the regressed data but they are in a range going from - 0.4 to 0.1 in the unregressed data. If we try to instead add some samples from the SCANB dataset as well randomly into the mix. How well does the scores get compared to the "ground truth"? ```{r, eval = first_run}scanb_samples <- df_pca %>% dplyr::filter(cohort == "scanb") %>% dplyr::slice_sample(n = 30) %>% dplyr::pull(sample_name)gsva_scores_embeddings_scanb_within_tcga_scanb <- parallel::mclapply( scanb_samples, function(x){ GSVA::gsva( df_pcs_regressed[, merged_col_data %>% dplyr::filter( cohort %in% c("tcga", "metabric", "scanb") ) %>% dplyr::mutate(weights = dplyr::case_when( cohort == "tcga" ~ 0.45, cohort == "metabric" ~ 0.45, cohort == "scanb" ~ 0.1 )) %>% dplyr::slice_sample(n = 150, weight_by = weights) %>% dplyr::pull(sample_name) %>% c(., x)], gene_sets_, verbose = FALSE ) }, mc.cores = 20)saveRDS( gsva_scores_embeddings_scanb_within_tcga_scanb, "../../results/rds_files/expanding_ember/gsva_scores_embeddings_scanb_within_tcga_scanb.rds")``````{r, fig.width=10, fig.height=5}lapply( gsva_scores_embeddings_scanb_within_tcga_scanb, function(x){ sapply( pathways_of_interest, get_merged_df_scores, df1 = x, df2 = df_pca %>% dplyr::filter(cohort == "scanb"), USE.NAMES = TRUE, simplify = FALSE ) %>% dplyr::bind_rows(.id = "pathway") }) %>% dplyr::bind_rows(.id = "sample_name") %>% ggplot2::ggplot(aes(x = df1, y = df2)) + ggplot2::geom_point() + ggplot2::facet_wrap(~pathway) + ggplot2::geom_abline(slope = 1, intercept = 0, color = "red") + ggplot2::labs( x = "GSVA scores from regressed data", y = "GSVA scores from unregressed data", title = "TCGA scores" ) + ggplot2::theme_bw()```It does not work so well when including some SCANB samples together with the METABRIC and TCGA samples. We are trying to achieve acorrelation of almost 1 with very low variability since we want to usethe scores clinically. Let us check the distribution of some genes for SCANB and TCGA afterregressing out the first two PCs.```{r, fig.width=10, fig.height=8}genes_histogram <- gene_sets_$HALLMARK_G2M_CHECKPOINTgenes_histogram <- intersect(genes_histogram, rownames(df_pcs_regressed))genes_histogram <- sample(genes_histogram, 30)genes_histogram <- c(genes_histogram, "MKI67") %>% uniquedf_pcs_regressed %>% t %>% data.frame %>% dplyr::select(dplyr::all_of(genes_histogram)) %>% tibble::rownames_to_column(var = "sample_name") %>% dplyr::inner_join( ., merged_col_data, by = "sample_name" ) %>% tidyr::pivot_longer( cols = dplyr::all_of(genes_histogram), values_to = "expression", names_to = "gene" ) %>% ggplot2::ggplot(aes( x = expression, fill = cohort, alpha = 0.5 )) + ggplot2::geom_density(alpha = 0.5) + ggplot2::facet_wrap(~gene, scales = "free") + ggplot2::theme_bw()```We see that even though the expression profile of the samples are overlapping there are discrepancies. That is why when using GSVA it does not work so well perhaps.## Scoring strategy with regressed dataWe now try to use a slightly different scoring strategy. We can think of our data in a log scale, so what we do now instead is to sum all of our genes of interest and then subtract an average of the housekeepinggenes expression levels.First we check the distribution of this average for each cohortseparately.```{r}hk_genes <- singscore::getStableGenes(50, type ="carcinoma", id ="geneid") %>%intersect(., rownames(df_pcs_regressed))avg_hkg_pcs_regressed <- df_pcs_regressed %>% t %>% data.frame %>% dplyr::select(dplyr::all_of(hk_genes)) %>% dplyr::mutate(avg_hkg =rowMeans(dplyr::select( ., dplyr::all_of(hk_genes) ))) %>% tibble::rownames_to_column(var ="sample_name") %>% dplyr::inner_join( ., merged_col_data,by ="sample_name" ) ``````{r, fig.width = 8, fig.height=6}#| label: fig-hkg-regressed#| fig-cap: Distribution of the average of the housekeeping genes#| for distinct cohorts. avg_hkg_pcs_regressed %>% ggplot2::ggplot(aes( x = avg_hkg, fill = cohort, alpha = 0.5 )) + ggplot2::geom_density(alpha = 0.5) + ggplot2::labs( x = "Average of housekeeping genes on regressed data", y = "Density" ) + ggplot2::theme_bw(base_size = 30) + ggplot2::theme( legend.position = c(0.8, 0.6), legend.background = element_blank() ) + change_guides_point() + change_plot_aes_point()```Indeed the tcga and metabric cohorts have an overlapping distribution, but the SCANB does not overlap completely, it isactually shifted. One should still take into account that the distributions are very close to 0, meaning that the housekeeping genes have very close to 0 values, as expected here in this case.We now calculate the score by taking this into account. ```{r}pathways_of_interest <-c("HALLMARK_ESTROGEN_RESPONSE_EARLY"="Estrogen Early","HALLMARK_G2M_CHECKPOINT"="G2M", "HALLMARK_E2F_TARGETS"="E2F", "SET_ERPR"="SET ER/PR","HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION"="EMT","HALLMARK_PI3K_AKT_MTOR_SIGNALING"="PI3K AKT MTOR","HALLMARK_DNA_REPAIR"="DNA Repair" ,"HALLMARK_INTERFERON_GAMMA_RESPONSE"="Interferon Gamma","random_200"="Random 200")``````{r, eval = first_run}scores <- sapply( gene_sets_[names(pathways_of_interest)], function(gene_set, df_pcs_regressed, avg_hkg_pcs_regressed){ proportion <- 1 nb_genes <- floor(proportion * length(gene_set)) gene_set <- intersect( sample(gene_set, nb_genes), rownames(df_pcs_regressed) ) # the code below was tried and it didnt work # 1) Mean of the genes and subtract the average of housekeeping genes # colMeans(df_pcs_regressed[gene_set, ]) - avg_hkg_pcs_regressed$avg_hkg # 2) top quantile. this one works surprisingly well considering # what was done. It could be further developped # apply( # X = df_pcs_regressed[gene_set, ], # MARGIN = 2, # quantile, # probs = 0.75 # ) # 3) pairwise differences of all genes. Small differences means genes # are going in the same direction. Big differences means genes are # going in opposite directions. # apply( # X = df_pcs_regressed[gene_set, ], # MARGIN = 2, # function(v){ # quantile(as.vector(dist(v)), probs = 0.95) # } # ) # 4) Scale all genes for each sample and then take the average of # the genes. Works quite well, still problem with SCANB # apply( # X = df_pcs_regressed, # MARGIN = 2, # function(v, name_genes, gene_set){ # mean(scale(v)[which(name_genes %in% gene_set)]) # }, # name_genes = rownames(df_pcs_regressed), # gene_set = gene_set # ) # 5) Scale and then calculate 100 times the score with subset of # genes and then take average value. # apply( # X = df_pcs_regressed[, sample(colnames(df_pcs_regressed), size = 500)], # MARGIN = 2, # function(v, name_genes, gene_set){ # # mean(sapply(1:100, # function(i, x, gene_set, name_genes){ # proportion <- 0.2 # nb_genes <- floor(proportion * length(gene_set)) # gene_set <- sample(gene_set, nb_genes) # mean(x[which(name_genes %in% gene_set)]) # }, # x = scale(v), # gene_set = gene_set, # name_genes = name_genes # )) # }, # name_genes = rownames(df_pcs_regressed), # gene_set = gene_set # ) colSums(df_pcs_regressed[gene_set, ]) }, df_pcs_regressed = df_pcs_regressed, avg_hkg_pcs_regressed = avg_hkg_pcs_regressed) %>% data.frame %>% tibble::rownames_to_column(var = "sample_name")scores <- dplyr::inner_join( scores %>% tidyr::pivot_longer( cols = dplyr::all_of(names(pathways_of_interest)), values_to = "score_hkg", names_to = "pathway" ), df_pca %>% tidyr::pivot_longer( cols = dplyr::all_of(names(pathways_of_interest)), values_to = "score_og", names_to = "pathway" ), by = c("sample_name", "pathway"))saveRDS( scores, "../../results/rds_files/expanding_ember/scores_regressed_only.rds")``````{r, fig.width=14, fig.height=7}#| label: fig-scores-regressed#| fig-cap: Scores obtained from regressed data#| of all the four cohorts TCGA, SCANB, METABRIC and POETIC compared to the #| original GSVA scores.scores %>% dplyr::filter(pathway %in% names(pathways_of_interest)) %>% dplyr::mutate(pathway = factor(pathway, levels = names(pathways_of_interest))) %>% ggplot2::ggplot(aes(x = score_og, y = score_hkg)) + ggplot2::geom_point() + ggplot2::facet_wrap( cohort ~ pathway, scales = "free", ncol = length(pathways_of_interest), labeller = as_labeller(c( pathways_of_interest, "metabric" = "METABRIC", "scanb" = "SCANB", "tcga" = "TCGA", "poetic" = "POETIC" )) ) + ggplot2::labs( x = "GSVA score", y = "Regressed score" ) + ggplot2::theme_bw()```The scores are actually highly correlated, specially the estrogen related pathways. Also the correlation between the scores in general follows the same trends.The plot below is a subset of the scores above to include in the publication.```{r, fig.height=11, fig.width=8}#| label: fig-scores-regressed-subset#| fig-cap: Scores obtained from regressed data#| of all the four cohorts TCGA, SCANB, METABRIC and POETIC compared to the #| original GSVA scores.pathways_of_interest_sub <- c( "HALLMARK_ESTROGEN_RESPONSE_EARLY" = "Estrogen Early", "HALLMARK_G2M_CHECKPOINT" = "G2M", "SET_ERPR" = "SET ER/PR", "HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION" = "EMT", "HALLMARK_DNA_REPAIR" = "DNA Repair")correlation_gsva_regressed <- scores %>% dplyr::filter(cohort %in% c("tcga", "scanb", "metabric")) %>% dplyr::group_by(cohort, pathway) %>% dplyr::summarise( correlation = cor(score_hkg, score_og, method = "spearman") ) %>% dplyr::inner_join( ., data.frame(pathway_name = pathways_of_interest_sub) %>% tibble::rownames_to_column(var = "pathway"), by = "pathway" ) %>% dplyr::mutate( corr_vals = paste0( toupper(cohort), "\n", pathway_name, ", rho: ", format(correlation, digits = 2) ) ) %>% dplyr::mutate(pathway = factor(pathway, names(pathways_of_interest_sub))) %>% dplyr::arrange(cohort, pathway) %>% dplyr::mutate(corr_vals = factor(corr_vals, levels = corr_vals)) %>% dplyr::inner_join( ., scores, by = c("cohort", "pathway") )correlation_only <- correlation_gsva_regressed %>% dplyr::filter(cohort %in% c("scanb", "metabric")) %>% dplyr::group_by(pathway, cohort) %>% dplyr::summarise( pathway = pathway[1], correlation = correlation[1], cohort = cohort[1] ) %>% dplyr::mutate(label = paste0( "\u03c1", ": ", format(correlation, digits = 2) ))correlation_gsva_regressed %>% dplyr::filter(cohort %in% c("scanb", "metabric")) %>% ggplot2::ggplot(aes(x = score_og, y = score_hkg)) + ggplot2::geom_point() + ggplot2::geom_smooth(method = "loess", formula = y~x) + ggplot2::facet_grid( pathway ~ cohort, labeller = as_labeller(c( pathways_of_interest_sub, c("metabric" = "METABRIC", "scanb" = "SCAN-B") )), scales = "free_y" ) + ggplot2::geom_label( data = correlation_only, mapping = aes(x = -0.5, y = Inf, label = label), hjust = 0.8, vjust = 1.5, size = 5, label.padding = grid::unit(0.3, "lines") ) + ggplot2::labs( x = "GSVA score", y = "Regressed score" ) + ggplot2::theme_bw(base_size = 20) + change_guides_point() + change_plot_aes_point()```We now compare the distributionsof these scores across the different cohorts and pathways of interest.```{r, fig.width=16, fig.height=8}scores %>% dplyr::filter(pathway %in% names(pathways_of_interest)) %>% dplyr::filter(cohort != "poetic") %>% dplyr::filter(pam50 %in% c("luma", "lumb", "her2", "basal")) %>% ggplot2::ggplot(aes(x = score_hkg, fill = cohort)) + ggplot2::geom_density(alpha = 0.5) + ggplot2::facet_wrap( pam50~pathway, scales = "free", ncol = length(pathways_of_interest), labeller = as_labeller(c( pathways_of_interest, "luma" = "Luminal A", "lumb" = "Luminal B", "her2" = "HER2", "basal" = "Basal" )) ) + ggplot2::theme_bw()```And with all molecular subtypes together.```{r, fig.width=10, fig.height=6}scores %>% dplyr::filter(pathway %in% names(pathways_of_interest)) %>% ggplot2::ggplot(aes(x = score_hkg, fill = cohort)) + ggplot2::geom_density(alpha = 0.5) + ggplot2::facet_wrap( ~pathway, scales = "free", labeller = as_labeller(pathways_of_interest) ) + ggplot2::theme_bw()```We see that the overlap is actually pretty good in general, even for SCANB. The only part where there is a bigger discrepancy is forG2M checkpoint. We see below that by calculating the GSVA score on the whole scanb cohort we don't have this problem.And as a comparison we plot with the original scores using GSVA on the whole cohort individually.```{r, fig.width=16, fig.height=8}scores %>% dplyr::filter(pathway %in% names(pathways_of_interest)) %>% dplyr::filter(pam50 %in% c("luma", "lumb", "her2", "basal")) %>% ggplot2::ggplot(aes(x = score_og, fill = cohort)) + ggplot2::geom_density(alpha = 0.5) + ggplot2::facet_wrap( pam50~pathway, scales = "free", ncol = length(pathways_of_interest), labeller = as_labeller(c( pathways_of_interest, "luma" = "Luminal A", "lumb" = "Luminal B", "her2" = "HER2", "basal" = "Basal" )) ) + ggplot2::theme_bw()```And all the subtypes together for the original score:```{r, fig.width=10, fig.height=6}scores %>% dplyr::filter(pathway %in% names(pathways_of_interest)) %>% ggplot2::ggplot(aes(x = score_og, fill = cohort)) + ggplot2::geom_density(alpha = 0.5) + ggplot2::facet_wrap( ~pathway, scales = "free", labeller = as_labeller(pathways_of_interest) ) + ggplot2::theme_bw()```We see that by doing GSVA the distributions they overlap much more than using the regressed data and the simple sum of the values for those genes.Still for estrogen signaling it seems that the estrogen early signatureis pretty robust.### Checking the patients from POETIC with new scoresWe now use the new scores to evaluate the comparison with the neighboorhood,just as before in the previous chapter where we used the POETIC trial data.```{r, eval = first_run}# get scores in the wide format so we can join with the original df_pca# dataframe and use the same code as in the previous scoring chapterscores_to_use <- c( "Estrogen response early", "E2F targets", "G2M", "P53 pathway", "EMT", "Androgen response", "TGFb signaling", "SET ER/PR") %>% `names<-`(paste0(c( "HALLMARK_ESTROGEN_RESPONSE_EARLY", "HALLMARK_E2F_TARGETS", "HALLMARK_G2M_CHECKPOINT", "HALLMARK_P53_PATHWAY", "HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION", "HALLMARK_ANDROGEN_RESPONSE", "HALLMARK_TGF_BETA_SIGNALING", "SET_ERPR")))scores_wide <- sapply( gene_sets_, function(gene_set, df_pcs_regressed, avg_hkg_pcs_regressed){ proportion <- 1 nb_genes <- floor(proportion * length(gene_set)) gene_set <- intersect( sample(gene_set, nb_genes), rownames(df_pcs_regressed) ) colSums(df_pcs_regressed[gene_set, ]) }, df_pcs_regressed = df_pcs_regressed, avg_hkg_pcs_regressed = avg_hkg_pcs_regressed) %>% data.frame %>% tibble::rownames_to_column(var = "sample_name")df_pca_scores <- dplyr::inner_join( df_pca, scores_wide, by = "sample_name", suffix = c("_og", "_new"))# arguments for getting the neighborhood scorepatients <- c("treated_nb63_baseline", "treated_nb236_baseline")names(scores_to_use) <- paste0(names(scores_to_use), "_new")pipeline_scores_plots_new_scores <- sapply( patients, get_patient_scores_distributions_all, df_pca = df_pca_scores, scores_to_use = scores_to_use, base_size = 20, USE.NAMES = TRUE, simplify = FALSE)saveRDS( pipeline_scores_plots_new_scores, "../../results/rds_files/expanding_ember/pipeline_scores_plots_new_scores.rds")saveRDS( df_pca_scores, "../../results/rds_files/expanding_ember/df_pca_scores.rds")```Patient 63 @fig-pt63 is considered a responder. According to the scores, when comparing the estrogen early signature to its average distribution in the neighborhood, the score is higher.```{r, fig.height=8, fig.width=10}#| label: fig-pt63#| fig-cap: Posterior distribution of the average scores in the neighborhood#| of patient 63 from POETIC trial. Each dot corresponds to a 1% quantile.pipeline_scores_plots_new_scores$treated_nb63_baseline$plot + change_plot_aes_point()```Patient 236 @fig-pt236 was considered a non responder. According to the scores, when comparing the estrogen early signature to its average distribution in the neighborhood, the score is lower, being in the5% quantile.```{r, fig.height=8, fig.width=10}#| label: fig-pt236#| fig-cap: Posterior distribution of the average scores in the neighborhood#| of patient 236 from POETIC trial. Each dot corresponds to a 1% quantile.pipeline_scores_plots_new_scores$treated_nb236_baseline$plot + change_plot_aes_point()```When comparing these two patients, there is also a difference in the androgenresponse score, which could be a reflection of different estrogen signaling.It reflects what we saw previously as well. ### Responder vs non responder comparison of new scoresWe now compare the scores for responders and non responders.```{r, fig.width=8, fig.height=5}df_pca_scores %>% dplyr::filter( cohort == "poetic" & timepoint == "baseline" & is_responder != "not_available" ) %>% ggplot2::ggplot(aes( color = is_responder, y = HALLMARK_ESTROGEN_RESPONSE_EARLY_new, x = HALLMARK_E2F_TARGETS_new )) + ggplot2::geom_point() + ggplot2::geom_smooth(method = "lm", formula = y~x) + ggplot2::labs( y = "Estrogen Early", x = "E2F targets", title = "Scores calculated after regressing the data" ) + ggplot2::theme_bw(base_size = 20) + change_plot_aes_point()```The higher E2F targets in average the lower the estrogen early score isfor non responders, whereas this correlation does not exist for responderpatients. This difference is mostly drive by the high E2F target non respondertumors. Now the plot below shows the correlation for baselien Ki67% and E2F targetsfor the score calculated in the regressed data in a single sample manner. We see a positive correlation between the two scores. Moreover, it is interestingto see that when the tumor has low Ki67, there is still a spectrum on the E2F targets score. Also there is no difference in the correlation between responders and non responders.```{r, fig.width=8, fig.height=5}df_pca_scores %>% dplyr::filter( cohort == "poetic" & timepoint == "baseline" & is_responder != "not_available" ) %>% ggplot2::ggplot(aes( color = is_responder, y = ki67, x = HALLMARK_E2F_TARGETS_new )) + ggplot2::geom_point() + ggplot2::geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs")) + ggplot2::labs( y = "Ki67%", x = "E2F targets", title = "Scores calculated after regressing the data" ) + ggplot2::theme_bw(base_size = 20) + change_plot_aes_point()```And lastly we compare the estrogen signaling signatures betweenresponders and non-responder.```{r, fig.width=10, fig.height=6}plot_responders_non_responder_comparison <- function( df_pca_scores, og_or_new = "new", pathways = c( "SET_ERPR" = "SET ER/PR", "HALLMARK_ESTROGEN_RESPONSE_EARLY" = "Estrogen early" )){ pathways_labeller <- pathways names(pathways_labeller) <- paste0( names(pathways), "_", og_or_new ) df_pca_scores %>% dplyr::filter( cohort == "poetic" & timepoint == "baseline" & is_responder != "not_available" ) %>% tidyr::pivot_longer( cols = dplyr::all_of( paste0( names(pathways), "_", og_or_new ) ), names_to = "pathway", values_to = "score" ) %>% ggplot2::ggplot(aes( color = is_responder, y = score, x = is_responder )) + ggplot2::geom_boxplot(outlier.shape = NA) + ggplot2::geom_jitter() + ggplot2::labs( x = "Is responder?", y = ifelse(og_or_new == "new", "Scores with regressed data", "GSVA scores") ) + ggplot2::facet_wrap( ~pathway, labeller = as_labeller(pathways_labeller), scales = "free_y" ) + ggplot2::theme_bw(base_size = 30) + ggplot2::theme(legend.position = "none") + change_plot_aes_point()}regressed_plot_er <- plot_responders_non_responder_comparison(df_pca_scores)regressed_plot_er```We see that the estrogen response early has a wider range when compared to theSET ER/PR score. That makes sense as this signature has over 100 genes,whereas SET ER/PR has only 18. Also the responderwas very good in discriminating the responders and non responders.What we can conclude from this figure is that the sampleswith very low scores are usually non responders, which reflecttheir position in the molecular landscape, also in general responders have higher ER signaling than non responders.Below is the figure with the GSVA scores before regressing the data, we see that SET ER/PR is not able to really distinguish completely the non-responders with very low score similarto what was done with GSVA. Even estrogen early hadsome differences.```{r, fig.width=10, fig.height=6}gsva_plot_er <- plot_responders_non_responder_comparison( df_pca_scores, og_or_new = "og")gsva_plot_er```And below is a figure with both GSVA and regressed scores together.```{r, fig.width=10, fig.height=10}#| label: fig-comparison-scoring-strategy-poetic#| fig-cap: Comparing scoring strategies for responders and non responders#| in the POETIC dataset. cowplot::plot_grid( regressed_plot_er, gsva_plot_er, ncol = 1)```Below we show the correlation betweenthese scores for all cohorts.```{r, fig.width=6, fig.height=8}df_pca_scores %>% #dplyr::filter(cohort != "poetic") %>% ggplot2::ggplot(aes( x = HALLMARK_ESTROGEN_RESPONSE_EARLY_new, y = SET_ERPR_new, color = pam50 )) + ggplot2::geom_point() + ggplot2::geom_smooth( color = "black", alpha = 0.5, method = "gam", formula = y ~ s(x, bs = "cs") ) + ggplot2::facet_wrap(~cohort, ncol = 1) + ggplot2::theme_bw(base_size = 20) + ggplot2::scale_color_manual( values = get_colors_pam50( df_pca_scores %>% dplyr::filter(cohort != "poetic") ) ) + ggplot2::labs(x = "Estrogen Early", y = "SET ER/PR") + change_guides_point() + change_plot_aes_point()```These scores are highly correlated but in different absolutescales. We now check the change in Ki67 for all patients and compare the scores with the original ones obtained with GSVA.```{r, fig.width=12, fig.height=6}#| label: fig-comparison-og-regressed-er#| fig-cap: Comparison of original GSVA and regressed scores between responders#| and non responders compared to change in Ki67.df_pca_scores %>% dplyr::filter( cohort == "poetic" & timepoint == "baseline" & is_responder != "not_available" ) %>% tidyr::pivot_longer( cols = c( "HALLMARK_ESTROGEN_RESPONSE_EARLY_og", "HALLMARK_ESTROGEN_RESPONSE_EARLY_new", "SET_ERPR_og", "SET_ERPR_new" ), names_to = "pathway", values_to = "score" ) %>% ggplot2::ggplot(aes( x = score, y = change_ki67 )) + ggplot2::geom_smooth(method = "lm", formula = "y~x") + ggplot2::geom_point() + ggplot2::facet_wrap( pathway~is_responder, scales = "free", ncol = 4, labeller = as_labeller(c( "non_responder" = "Non-responder", "responder" = "Responder", "HALLMARK_ESTROGEN_RESPONSE_EARLY_og" = "GSVA estrogen early", "HALLMARK_ESTROGEN_RESPONSE_EARLY_new" = "Regressed estrogen early", "SET_ERPR_og" = "GSVA SET ER/PR", "SET_ERPR_new" = "Regressed SET ER/PR" )) ) + ggplot2::labs( x = "Scores", y = "Change in Ki67 (%)" ) + ggplot2::theme_bw(base_size = 15) + change_guides_point() + change_plot_aes_point()```We see that the bigger the change the higher the score is when using theregressed data. Also the non responders tend to have scores mostly inthe negative scale, whereas the responders are more shifted to theright. SET ER/PR is also a good measure here. ```{r}df_pca_scores %>% dplyr::filter( cohort =="poetic"& timepoint =="baseline"& is_responder !="not_available" ) %>% ggplot2::ggplot(aes(x = HALLMARK_ESTROGEN_RESPONSE_EARLY_og,y = HALLMARK_ESTROGEN_RESPONSE_EARLY_new,color = is_responder )) + ggplot2::geom_smooth(method ="gam",formula = y ~s(x, bs ="cs"), color ="black" ) + ggplot2::geom_point() + ggplot2::labs(x ="GSVA Estrogen early",y ="Regressed Estrogen early" ) + ggplot2::theme_bw(base_size =15) +change_guides_point() +change_plot_aes_point()```There is a very good match between the two scores in general,meaning that the regression scoring strategy capture relativelywell the scores. There is one patient that is a non-responderand has a low regressed estrogen early but a GSVA score close to 0, let us check this patient.```{r}df_pca_scores %>% dplyr::filter( is_responder =="non_responder"& dplyr::between(HALLMARK_ESTROGEN_RESPONSE_EARLY_og, -0.1, 0.1) & dplyr::between(HALLMARK_ESTROGEN_RESPONSE_EARLY_new, -20, -15) ) %>% dplyr::select(patient_nb, ki67, PC3, change_ki67, er_status) %>% DT::datatable()```It is a patient that is far to the left on the molecular landscape, among thebasal like, and had an increase in Ki67 upon ET. So the new scoring system was able to capture this patient as with low score. ### Survival analysis with the new scoresWe can check how robust these scores are by performing survival analysis.```{r, eval = first_run}tcga_samples <- colData(datasets$tcga) %>% data.frame %>% dplyr::filter( pam50 %in% c("luma", "lumb") & node_stage != "NX" & !(tumor_stage %in% c("stage_iv", "na")) & er_status == "pos" ) %>% dplyr::pull(sample_name)scanb_samples <- colData(datasets$scanb) %>% data.frame %>% dplyr::filter( node_stage != "NX" & !(tumor_stage %in% c("T4", "Tis", "TX")) & er_status == "pos" & TreatGroup == "Endo" ) %>% dplyr::pull(sample_name)metabric_samples <- colData(datasets$metabric) %>% data.frame %>% dplyr::filter( CHEMOTHERAPY == "NO" & er_status == "pos" & HORMONE_THERAPY == "YES" ) %>% dplyr::pull(sample_name)formulas_survival <- c( "os_tcga" = "Surv(os_months, os_status) ~ age + node_stage + tumor_stage", "os_scanb" = "Surv(os_months, os_status) ~ age + node_stage + tumor_stage", "os_metabric" = "Surv(os_months, os_status) ~ age + npi", "rfs_metabric" = "Surv(rfs_months, rfs_status) ~ age + npi", "rfs_scanb" = "Surv(rfs_months, rfs_status) ~ age + node_stage + tumor_stage")type_survival <- c("os", "rfs")which_scores <- c( paste0(c( "HALLMARK_G2M_CHECKPOINT", "HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION", "HALLMARK_DNA_REPAIR", "HALLMARK_ANDROGEN_RESPONSE", "HALLMARK_PI3K_AKT_MTOR_SIGNALING", "SET_ERPR", "HALLMARK_ESTROGEN_RESPONSE_EARLY" ), "_new"))survival_results <- sapply( c("os", "rfs"), function(type_analysis, datasets, name_scores, formulas){ mapply( function( dataset, name_dataset, name_scores, formulas, type_analysis ){ if (type_analysis == "rfs" & name_dataset == "tcga"){ return() } else { sapply( name_scores, function(name_score, col_data, formula){ col_data[, name_score] <- base::scale( col_data[, name_score] ) survival::coxph( as.formula( paste(formula, name_score, sep = "+") ), data = col_data, y = FALSE, x = FALSE ) }, col_data = dataset, formula = formulas[ grepl( paste(type_analysis, name_dataset, sep = "_"), names(formulas) ) ], USE.NAMES = TRUE, simplify = FALSE ) } }, dataset = datasets, name_dataset = names(datasets), MoreArgs = list( formulas = formulas, name_scores = name_scores, type_analysis = type_analysis ), USE.NAMES = TRUE, SIMPLIFY = FALSE ) }, datasets = lapply( list( "tcga" = tcga_samples, "scanb" = scanb_samples, "metabric" = metabric_samples ), function(x) df_pca_scores %>% dplyr::filter(sample_name %in% x) ), name_scores = which_scores, formulas = formulas_survival, USE.NAMES = TRUE, simplify = FALSE)survival_results$rfs <- survival_results$rfs[ !sapply(survival_results$rfs, is.null)]survival_results$rfs$metabric <- survival_results$rfs$metabric[ !sapply(survival_results$rfs$metabric, is.null)]survival_results$os <- purrr::discard( purrr::map( survival_results$os, ~ purrr::discard(.x, is.null), ), is.null)# we cannot simply save the models as each model has some # environment variables, which adds up to over 20GB. # check this stack exchange thread to read more on it:# https://stackoverflow.com/questions/42230920/saverds-inflating-size-of-object/52372480# the solution is to basically clear the environment from the terms # object. since it is pretty fast to run the survival analysis# we will not save the objects.# we now proceed to prepare the plots. since the survival result is # actually a large file, it is best to do all the plottings, save# them in other rds/pdf files and then use on the quarto markdown.# otherwise it is too slow to render the book. # the same is true for the statistics and coefficients available.names_signatures <- c( "HALLMARK_G2M_CHECKPOINT" = "G2M checkpoint", "HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION" = "EMT", "HALLMARK_DNA_REPAIR" = "DNA repair", "HALLMARK_ANDROGEN_RESPONSE" = "Androgen response", "HALLMARK_PI3K_AKT_MTOR_SIGNALING" = "PI3K AKT MTOR signaling", "SET_ERPR" = "SET ER/PR", "HALLMARK_ESTROGEN_RESPONSE_EARLY" = "Estrogen early")names(names_signatures) <- paste0(names(names_signatures), "_new")names_coefficients <- list( metabric = c( "age" = "Age", "npi" = "NPI", names_signatures ), scanb = c( "age" = "age", names_signatures, "node_stageN1" = "N1", "node_stageN2and3" = "N2 and N3", "tumor_stageT1" = "T1", "tumor_stageT2" = "T2", "tumor_stageT3" = "T3" ), tcga = c( "age" = "age", "tumor_stage" = "Tumor Stage", names_signatures, "node_stageN1" = "N1", "node_stageN2" = "N2", "node_stageN3" = "N3", "tumor_stagestage_ii" = "T2", "tumor_stagestage_iii" = "T3" ))patients <- list( tcga = "Lum A/B, ER+ BC", scanb = "Endo Only, ER+ BC", metabric = "Endo Only, ER+ BC")analysis_code <- list( os = "Overall survival", rfs = "Recurrence free survival")forest_plots <- mapply( function(fits, type_analysis, names_signatures){ mapply( function(cohort_fits, name_cohort, type_analysis, names_signatures){ tidy_survival <- get_df_survival( cohort_fits, pathways_of_interest = names(names_signatures) ) plot_combined_scores( tidy_survival, range_min = 0.6, range_hr = 1.5, names_signatures = names_signatures ) + ggplot2::labs( title = paste0( toupper(name_cohort), " ", patients[[name_cohort]], "\n", analysis_code[[type_analysis]] ) ) }, cohort_fits = fits, name_cohort = names(fits), MoreArgs = list( type_analysis = type_analysis, names_signatures = names_signatures ), USE.NAMES = TRUE, SIMPLIFY = FALSE ) }, survival_results, names(survival_results), MoreArgs = list(names_signatures = names_signatures), USE.NAMES = TRUE, SIMPLIFY = FALSE)saveRDS( forest_plots, "../../results/rds_files/expanding_ember/forest_plots.rds")# and now we fetch the tables that will be used later on including the# confidence intervals and other parameters from the fittables_survival <- lapply( survival_results, function(x) lapply( x, function(y) lapply( y, function(z) broom::tidy(z) ) %>% dplyr::bind_rows(.id = "score") ) %>% dplyr::bind_rows(.id = "cohort")) %>% dplyr::bind_rows(.id = "type_analysis") %>% dplyr::mutate(HR = exp(estimate))write.csv( tables_survival, "../../results/tables/expanding_ember/survival_results.csv", row.names = FALSE)``````{r, fig.width = 9, fig.height=4, warning = FALSE}#| label: fig-pca-mol-land-survival-regressed#| fig-cap: Overall survival analysis from SCANB and METABRIC cohorts and their#| scores. The formulas used were the same as for the estrogen#| signaling analysis. Coefficients were scaled before performing#| cox regressionforest_plots <- readRDS("../../results/rds_files/expanding_ember/forest_plots.rds")# we remove the TCGA plot so we have actually 4 plots and they are # ordered nicely. forest_plots$os_wo_tcga <- forest_plots$osforest_plots$os_wo_tcga$tcga <- NULLcowplot::plot_grid(plotlist = c( forest_plots$os_wo_tcga, forest_plots$rfs), nrow = 2)```The plot with TCGA is shown below.```{r, fig.width=4.5, fig.height=10}cowplot::plot_grid(plotlist = c( forest_plots$os, forest_plots$rfs), ncol = 1)```Scores for TCGA are noisier than SCANB and METABRIC. Though thescaled scores they have comparable hazard ratios and also they follow what we saw previously. The only pathway that is a bit different is the PI3K AKT MTOR signaling. This pathway had a noisiercorrelation with the GSVA score as well.```{r}read.csv("../../results/tables/expanding_ember/survival_results.csv") %>% DT::datatable(options =list(scrollX =TRUE), filter ='top') %>% DT::formatRound(columns=c("estimate", "std.error", "statistic", "HR" ), digits =2 ) %>% DT::formatSignif(columns =c("p.value"))```## Regressing the PDXsWe can use the regressing strategy to score the PDXs and then evaluatetheir scores. ```{r, eval = first_run}# first get the regressed datapdx_regressed <- get_regressed_data( sum_exp = pdx_tpm, which_exp = "log2tpm", pca_fit = pca_fit_all_genes_wo_outliers, stable_genes = stable_genes) %>% # calculate the scores for the regressed data get_scores_regressed( sum_exp = ., gene_sets = gene_sets_ )pdx_regressed$cohort <- "pdx"saveRDS( pdx_regressed, "../../results/rds_files/expanding_ember/pdx_regressed.rds")```We start by comparing the scores across the different control samples and their positions in the molecular landscape.```{r fig.width=9, fig.height=6}#| label: fig-pca-pdx-control-only-regressed#| fig-cap: Embedding of only regressed PDX control samples on top of the #| METABRIC, SCANB and TCGA samplesp <- get_base_plot( df_pca_coordinates_wo_outliers %>% dplyr::filter(cohort != "poetic"))pdx_df_pca_regressed_sub <- colData(pdx_regressed) %>% data.frame %>% dplyr::filter(cohort == "pdx" & treatment == "CTRL") %>% dplyr::mutate(pam50 = "nc")p + ggplot2::geom_point( pdx_df_pca_regressed_sub, mapping = aes(x = PC3, y = PC4, shape = pdx), size = 5 ) + ggplot2::theme_bw(base_size = 15) + ggplot2::labs( caption = "Grey points correspond to the PDX cohort", title = "PDX cohort, only control samples" ) + ggplot2::scale_color_manual( values = c( get_colors_pam50(p$data), "not available" = "grey" ) ) + change_plot_aes_point() + change_guides_point(shape = TRUE)```The results are jus twhat we got previously as well, meaning thatby using all these genes the information of the PDXs are still captured. The main differences is that the luminal B region is morecompact compare to @fig-pca-pdx-control-only.And now that we have the results we can compare the PDXs as well. ```{r, fig.width=10, fig.height=6}#| label: fig-pdx-regressed-scores#| fig-cap: Scores obtained from the regressed data of the PDXs.col_data_pdx_regressed <- colData(pdx_regressed) %>% data.framepathways_pdx <- paste0("regressed_", c(paste0("HALLMARK_", c( "ESTROGEN_RESPONSE_EARLY", "G2M_CHECKPOINT", "E2F_TARGETS", "ANDROGEN_RESPONSE", "APOPTOSIS", "MTORC1_SIGNALING", "EPITHELIAL_MESENCHYMAL_TRANSITION", "DNA_REPAIR" )), "SET_ERPR", "random_200"))labeller_names <- c( "Estrogen early", "G2M", "E2F", "Androgen response", "Apoptosis", "MTORC1 signaling", "EMT", "DNA Repair", "SET ER/PR", "Random 200") %>% `names<-`(pathways_pdx)col_data_pdx_regressed %>% dplyr::filter(treatment == "CTRL") %>% tidyr::pivot_longer( cols = dplyr::all_of(pathways_pdx), names_to = "pathway", values_to = "score" ) %>% ggplot2::ggplot(aes(y = pdx, x = score)) + ggplot2::geom_boxplot() + ggplot2::geom_jitter() + ggplot2::labs(x = "Regressed score", y = "PDX") + ggplot2::facet_wrap(~pathway, labeller = as_labeller(labeller_names)) + ggplot2::theme_bw(base_size = 15)```The random 200 is just a gene set with 200 random genes that works as a control and serves as a comparison to the other pathways.And below we show the distribution of some of the scores calculated for all the other cohorts as a comparison. ```{r, fig.width=8, fig.height=5}scores_wide <- tidyr::pivot_wider( scores, id_cols = c("sample_name", "cohort"), values_from = "score_hkg", names_from = "pathway")pathways_density <- stringr::str_split( pathways_pdx, pattern = "_", n = 2, simplify = TRUE)[, 2]scores %>% dplyr::filter(cohort != "poetic" & pathway %in% pathways_density) %>% ggplot2::ggplot(aes(x=score_hkg, fill = cohort)) + ggplot2::geom_density(alpha = 0.5) + ggplot2::facet_wrap(~pathway, scales = "free") + ggplot2::theme_bw()```We see that METS15 is the one with the highest proliferation andlowest EMT, it is a PDX that comes from a pleural efusion. Alsoit is the PDX with the lowest apoptosis and highest DNA repair,probably due to a higher replication rate. Moreover, all thesePDXs they have a estrogen response early scores higher than 0in average, which is about the average of the scores in theER+ BC samples.Now we check what happens with some of the PDXs when theyare treated with P4, to compare with @fig-pdx-p4-control-pathways.```{r, fig.width=13, fig.height=15}#| label: fig-pdx-p4-control-pathways-regressed.#| fig-cap: Comparison of position in the molecular landscape between#| CTRL, E2 and P4 treated samples with the regressed datapathways <- c( #"HALLMARK_ANDROGEN_RESPONSE" = "Androgen Response", #"HALLMARK_E2F_TARGETS" = "E2F", "HALLMARK_G2M_CHECKPOINT" = "G2M", "HALLMARK_ESTROGEN_RESPONSE_EARLY" = "Estrogen Early", #"SET_ERPR" = "SET ER/PR", "HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION" = "EMT", "GOBP_RESPONSE_TO_PROGESTERONE" = "GO Progesterone", "WILCOX_RESPONSE_TO_PROGESTERONE_UP" = "W. Prog UP")names(pathways) <- paste0("regressed_", names(pathways))pdxs_to_use <- c("METS15", "T113", "T111", "T105", "T109", "T110")names(pdxs_to_use) <- pdxs_to_usepdx_df_pca_sub <- col_data_pdx_regressed %>% dplyr::filter( cohort == "pdx" & treatment %in% c("CTRL", "P4", "E2") ) %>% dplyr::mutate(pam50 = "nc") %>% dplyr::mutate(pdx = factor(pdx, levels = c( "METS15", "T113", "T109", "T105", "T111", "T110" ))) %>% dplyr::filter(pdx %in% pdxs_to_use)plots_pathways <- mapply( function(pathways, pathway_names, i){ names(pathways) <- pathway_names pdx_df_pca_sub %>% tidyr::pivot_longer( cols = dplyr::all_of(pathway_names), names_to = "pathway", values_to = "score" ) %>% dplyr::mutate(pathway = factor(pathway, levels = pathway_names)) %>% ggplot2::ggplot(aes(x = treatment, y = score)) + ggplot2::geom_boxplot(outlier.shape = NA) + ggplot2::geom_jitter( size = 3, alpha = 0.9, mapping = aes(color = treatment) ) + ggplot2::scale_color_viridis_d(option = "H") + ggplot2::facet_wrap( ~ pdx + pathway, scales = "fixed", nrow = length(pathway_names), labeller = as_labeller(c(pathways, pdxs_to_use)) ) + ggplot2::labs( x = ifelse(i == 4, "Treatment", ""), y = "Regressed scores" ) + ggplot2::scale_y_continuous(labels = scales::number_format( accuracy = 0.01, decimal.mark = '.' )) + ggplot2::theme_bw(base_size = 20) + ggplot2::theme(legend.position="none") + change_guides_point() + change_plot_aes_point() }, pathways = pathways, pathway_name = names(pathways), i = 1:length(pathways), SIMPLIFY = FALSE, USE.NAMES = TRUE)cowplot::plot_grid( plotlist = plots_pathways, nrow = length(plots_pathways) )```The results are very similar to what was seen previously using the GSVA. What is interesting here is that we have an absolute scale, so we can compare the scores.## singscoreWe can try to use singscore instead, it is a sample dependent measure so it does not estimate the distribution of the gene expression levels beforecalculating the enrichment score.```{r, eval = first_run}gene_sets_names <- setdiff(names(gene_sets_), p4_pathways$gs_name %>% unique)gene_sets_gsea <- mapply( function(gene_set, name_gs){ GSEABase::GeneSet( gene_set %>% unique, setName = name_gs ) }, gene_set = gene_sets_[gene_sets_names], name_gs = gene_sets_names)singscore_dfs <- mapply( function(sum_exp, gene_sets, which_exp){ singscore::multiScore( singscore::rankGenes(assay(sum_exp,which_exp)), upSetColc = gene_sets )[[1]] }, sum_exp = datasets, which_exp = c(which_exp, "poetic" = "normalized_intensity"), MoreArgs = list(gene_sets = gene_sets_gsea)) %>% Reduce(cbind, .)saveRDS( singscore_dfs, "../../results/rds_files/expanding_ember/singscore_dfs.rds")saveRDS( gene_sets_gsea, "../../results/rds_files/expanding_ember/gene_sets_gsea.rds")```We start by comparing with the GSVA scores.```{r, fig.width=20, fig.height=16, dev='png'}#| label: fig-all-pathways-gsva-singscoresdf_all_scores <- singscore_dfs %>% t %>% data.frame %>% tibble::rownames_to_column(var = "sample_name") %>% tidyr::pivot_longer( cols = dplyr::all_of(names(gene_sets_gsea)), names_to = "pathway", values_to = "singscore" ) %>% dplyr::inner_join( merged_col_data %>% tidyr::pivot_longer( cols = dplyr::all_of(names(gene_sets_gsea)), names_to = "pathway", values_to = "gsva" ), ., by = c("sample_name", "pathway") ) df_all_scores %>% ggplot2::ggplot(aes( x = singscore, y = gsva, color = cohort )) + ggplot2::geom_point(alpha = 0.3) + ggplot2::facet_wrap(~pathway, scales = "free") + ggplot2::theme_bw()```We see that in all cases there is a correlation, but the interpretationchanges. In some of the pathways there is difference in the singscoresbased on the cohort, this is not seen on GSVA. ```{r, fig.width=12, fig.height=5}#| label: fig-selected-pathways-gsva-singscorespathway_names <- c( "HALLMARK_ESTROGEN_RESPONSE_EARLY" = "Estrogen\nEarly", "HALLMARK_G2M_CHECKPOINT" = "G2M", "HALLMARK_EPITHELIAL_MESENCHYMAL_TRANSITION" = "EMT", #"SET_ERPR" = "SET ER/PR", "HALLMARK_DNA_REPAIR" = "DNA Repair", "HALLMARK_ANDROGEN_RESPONSE" = "Androgen\nResponse", "HALLMARK_PI3K_AKT_MTOR_SIGNALING" = "PI3K AKT\nMTOR Signaling", "HALLMARK_MYC_TARGETS_V1" = "MYC\ntargets V1", "random_200" = "Random\n200 genes", "scanb" = "SCAN-B", "metabric" = "METABRIC", "tcga" = "TCGA")df_all_scores %>% dplyr::filter( pathway %in% names(pathway_names) & cohort %in% c("tcga", "metabric", "scanb") ) %>% ggplot2::ggplot(aes( x = singscore, y = gsva, color = cohort )) + ggplot2::geom_point(alpha = 0.3) + ggplot2::facet_grid( cohort~pathway, scales = "free", labeller = as_labeller(pathway_names) ) + ggplot2::theme_bw(base_size = 15) + ggplot2::theme(legend.position = "none")```The next figure shows the same comparison but instead of using singscore, we used ssGSEA.```{r, eval = first_run}ssgsea_dfs <- mapply( function(sum_exp, gene_sets, which_exp){ GSVA::gsva( expr = assay(sum_exp,which_exp) %>% as.matrix, gset.idx.list = gene_sets, method = "ssgsea", ssgsea.norm = FALSE, verbose = FALSE ) }, sum_exp = datasets, which_exp = c(which_exp, "poetic" = "normalized_intensity"), MoreArgs = list(gene_sets = gene_sets_))ssgsea_dfs <- lapply(ssgsea_dfs, t)ssgsea_dfs <- Reduce(rbind, x = ssgsea_dfs)saveRDS( ssgsea_dfs, "../../results/rds_files/expanding_ember/ssgsea_dfs.rds")``````{r, fig.width=12, fig.height=5}ssgsea_dfs_gsva <- ssgsea_dfs %>% data.frame %>% tibble::rownames_to_column(var = "sample_name") %>% tidyr::pivot_longer( cols = dplyr::all_of(names(gene_sets_)), names_to = "pathway", values_to = "ssGSEA" ) %>% dplyr::inner_join( merged_col_data %>% tidyr::pivot_longer( cols = dplyr::all_of(names(gene_sets_gsea)), names_to = "pathway", values_to = "gsva" ), ., by = c("sample_name", "pathway") ) ssgsea_dfs_gsva %>% dplyr::filter( pathway %in% names(pathway_names) & cohort %in% c("tcga", "metabric", "scanb") ) %>% ggplot2::ggplot(aes( x = ssGSEA, y = gsva, color = cohort )) + ggplot2::geom_point(alpha = 0.3) + ggplot2::facet_grid( cohort~pathway, scales = "free_y", labeller = as_labeller(pathway_names) ) + ggplot2::theme_bw(base_size = 15) + ggplot2::theme(legend.position = "none")```The picture is similar as before, but now we actually look at the distributionsacross the 3 big cohorts. We used ssGSEA without the normalization, as thatwould be necessary in the case of an individual sample. ```{r, fig.width=12, fig.height=6}#| label: fig-ssgsea-distsunique_pathways <- intersect(names(pathway_names), unique(scores$pathway))ssgsea_dfs_gsva %>% dplyr::filter( pathway %in% unique_pathways & cohort %in% c("tcga", "metabric", "scanb") ) %>% dplyr::mutate(cohort = dplyr::case_when( cohort == "tcga" ~ "TCGA", cohort == "metabric" ~ "METABRIC", cohort == "scanb" ~ "SCAN-B" )) %>% ggplot2::ggplot(aes( x = ssGSEA, fill = cohort )) + ggplot2::geom_density(alpha = 0.3) + ggplot2::facet_wrap( ~pathway, scales = "free", labeller = as_labeller(pathway_names) ) + ggplot2::scale_y_continuous(labels = NULL, breaks = NULL) + ggplot2::scale_x_continuous(guide = guide_axis(angle = 45)) + ggplot2::labs( x = "ssGSEA", y = "Density", fill = "Cohort" ) + ggplot2::theme_bw(base_size = 20) + change_guides_point() + change_plot_aes_point()```We see that overall there is a discrepancy, sometimes big,depending on the pathway, including the random genespathway. Next we show the same distribution for singscore. Similarly there is a big discrepancy in several cases. ```{r, fig.width=10, fig.height=6}#| label: fig-singscore-distsdf_all_scores %>% dplyr::filter( pathway %in% unique_pathways & cohort %in% c("tcga", "metabric", "scanb") ) %>% dplyr::mutate(cohort = dplyr::case_when( cohort == "tcga" ~ "TCGA", cohort == "metabric" ~ "METABRIC", cohort == "scanb" ~ "SCAN-B" )) %>% ggplot2::ggplot(aes(x = singscore, fill = cohort)) + ggplot2::geom_density(alpha = 0.3) + ggplot2::facet_wrap( ~pathway, scales = "free", labeller = as_labeller(pathway_names) ) + ggplot2::scale_y_continuous(labels = NULL, breaks = NULL) + ggplot2::scale_x_continuous(guide = guide_axis(angle = 45)) + ggplot2::labs( x = "singscore", y = "Density", fill = "Cohort" ) + ggplot2::theme_bw(base_size = 20) + change_guides_point() + change_plot_aes_point()```But now, @fig-regressed-scores-dists shows that when we calculatethe scores with the regressed data using our methodology the distributionsare matched and adjusted, with the expection of G2M, which seems to be something more fundamental instead of batch effect. Note that all the distributions are overlapping significantly.```{r, fig.width=10, fig.height=6}#| label: fig-regressed-scores-distsscores %>% dplyr::filter(cohort %in% c("tcga", "scanb", "metabric")) %>% dplyr::mutate(cohort = dplyr::case_when( cohort == "tcga" ~ "TCGA", cohort == "metabric" ~ "METABRIC", cohort == "scanb" ~ "SCAN-B" )) %>% dplyr::filter(pathway %in% unique_pathways) %>% ggplot2::ggplot(aes( x = score_hkg, fill = cohort )) + ggplot2::geom_density(alpha = 0.3) + ggplot2::facet_wrap( ~pathway, scales = "free", labeller = as_labeller(pathway_names) ) + ggplot2::scale_y_continuous(labels = NULL, breaks = NULL) + ggplot2::scale_x_continuous(guide = guide_axis(angle = 45)) + ggplot2::labs( x = "Regressed score", y = "Density", fill = "Cohort" ) + ggplot2::theme_bw(base_size = 20) + change_guides_point() + change_plot_aes_point()```The next two figures are the distributions of the singscore and GSVAfilled by cohort.```{r, fig.width=20, fig.height=16, dev='png'}df_all_scores %>% ggplot2::ggplot(aes( x = singscore, fill = cohort, alpha = 0.5 )) + ggplot2::geom_density(position = "identity", alpha = 0.5) + ggplot2::facet_wrap(~pathway, scales = "free")```For several pathways in the singscore the distributions are similar,but that is not always the case.```{r, fig.width=20, fig.height=16, dev='png'}df_all_scores %>% ggplot2::ggplot(aes( x = gsva, fill = cohort )) + ggplot2::geom_density(position = "identity", alpha = 0.5) + ggplot2::facet_wrap(~pathway, scales = "free")```On the other hand GSVA gives very similar distributions for all the different cohorts. Therefore we actually need to use GSVA. It is important in the end to calculate scores based on the cohort. We now move on and try the same analysis on the regressed data.```{r, eval = first_run}singscore_dfs_regressed <- singscore::multiScore( singscore::rankGenes(df_pcs_regressed), upSetColc = gene_sets_gsea)[[1]]saveRDS( singscore_dfs_regressed, "../../results/rds_files/expanding_ember/singscore_dfs_regressed.rds")```We start by comparing with the GSVA scores.```{r, fig.width=20, fig.height=16, dev='png'}df_all_scores_regressed <- singscore_dfs_regressed %>% t %>% data.frame %>% tibble::rownames_to_column(var = "sample_name") %>% tidyr::pivot_longer( cols = dplyr::all_of(names(gene_sets_gsea)), names_to = "pathway", values_to = "singscore" ) %>% dplyr::inner_join( merged_col_data %>% tidyr::pivot_longer( cols = dplyr::all_of(names(gene_sets_gsea)), names_to = "pathway", values_to = "gsva" ), ., by = c("sample_name", "pathway") ) df_all_scores_regressed %>% ggplot2::ggplot(aes( x = singscore, y = gsva, color = cohort )) + ggplot2::geom_point() + ggplot2::facet_wrap(~pathway, scales = "free") + ggplot2::theme_bw()```We see that in all cases there is a correlation, but the interpretationchanges. In some of the pathways there is difference in the singscoresbased on the cohort, this is not seen on GSVA. The next two figures are the distributions of the singscore and GSVAfilled by cohort.```{r, fig.width=20, fig.height=16, dev='png'}df_all_scores_regressed %>% ggplot2::ggplot(aes( x = singscore, fill = cohort )) + ggplot2::geom_density(position = "identity", alpha = 0.5) + ggplot2::facet_wrap(~pathway, scales = "free")```In the end the best way of scoring seems to be using GSVA on the unregressed data though it depends on the pathways. For example thehallmark estrogen response early and set ER/PR pathways seem to have been regressed quite well, so we can actually compare the results using the scores. On the other hand we can't use the pathways G2M checkpoint,E2F targets and EMT. For the PI3K signaling score it seems it is comparable to SCANB only.